編輯:關於Android編程
Solr是一個可擴展的,可快速部署的,對搜索海量文本中心的數據和對返回結果做相關性排序方面做了優化的企業級搜索引擎。
可擴展性:Solr可以把建立索引和查詢處理的運算分布到一個集群內的多台服務器上。
快速部署:Solr是開源軟件,安裝和配置都很方便,可以根據安裝包內的Sample配置直接上手。
優化的搜索功能:Solr搜索夠快。對於復雜的搜索查詢,Solr可以做到亞秒級的處理,通常幾十毫秒就能處理完一次復雜查詢
海量文本:Solr是針對百萬級以上的海量文本處理而設計的,可以很好地處理海量數據。
文本中心的數據:Solr為搜索包含自然語言的文本內容做了優化,比如電子郵件,網頁,簡歷,PDF文檔,或是推特、微博、博客這些社交內容等等,都適合用Solr來處理。
結果是按相關性排序的:Solr的搜索返回結果是按照結果文檔與用戶查詢之間的相關程度度做排序的,保證最相關的結果會優先返回。
適合用類似Solr這樣的搜索引擎來處理的數據的5種主要特點:
文本中心數據(text-centric data)
讀取遠多於寫入的數據
面向文檔的數據
靈活的Schema
海量數的據量,也就是”大數據“搜索引擎的設計初衷就是用來提取文本數據的隱含結構,並生成相關索引以提高查詢檢索的效率。“文本中心數據”這個詞隱含表明了文檔中的文本信息包含用戶感興趣的查詢內容。當然,搜索引擎也支持非文本數據,比如數字類型的數據,但是其主要強項,還是在於處理基於自然語言的文本數據。
前面說的都是“文本”,其實“中心”這個部分也很重要,因為如果你的用戶對於文本部分的內容不感興趣,那麼搜索引擎可能就不是處理你的問題的最佳選擇。舉個例子,對於一個給員工用來創建差旅支出報告的應用,每份報告都包括一些結構化的數據,比如日期,費用類型,匯率,數量等等,另外每項費用後面可能會包含一些備注信息,用於描述該項費用的大致情況。這樣一個應用就是一個包含文本信息,但並不是“文本中心的數據”的一個例子,因為會計部門在使用這些員工的支出費用報告來生成月度支出報告時,並不會通過查找備注裡的文本信息來做,文本在這裡並不是其關心的主要內容。簡單來說,就是不是所有包含文本信息的數據都適合搜索引擎來處理。
首先,需要聲明的是Solr是允許你更新索引中的現有文檔內容的。你可以把“讀取遠多於寫入”解讀為對於文檔的讀取操作頻率要遠遠高於創建文檔和更新文檔的頻率。但是別狹隘的理解為你就完全不能寫入數據了,或是你會被限制在一個特定頻率之下更新數據。事實上Solr4的一個關鍵特性就是“近乎實時的查詢”,這個功能可以允許你每秒鐘為數千的文檔建立索引並且幾乎立刻就能查詢到這些新加入的文檔。
“讀取遠多於寫入的數據”背後的關鍵點是你的數據在寫入Solr後,在其生命周期內應該是要被重復讀取很多次的。你可以理解為搜索引擎並不是主要用來存儲數據的,而是主要用於查詢存儲的數據的(查詢請求是一種讀取操作)。
一個文檔是由值域(field)組成的獨立集合,每一個值域都只保存數據值,不能再嵌套包含其他值域。換句話說,在Solr這樣的搜索引擎中,文檔都是扁平結構的,文檔之間不存在相互依賴關系。Solr中“扁平”的概念是比較寬松的,一個值域可以保存多個數據值,但是值域不能再嵌套包含子值域。也就是說你可以在一個值域裡存儲多個數據值,但是你不能往值域裡頭嵌套別的值域。
在關系型數據庫中,表中的每一行數據都必須擁有相同的結構。而在Solr中,文檔們可以有不同的值域。當然同一個索引中的文檔們至少應該擁有一部分大家都有的值域以便於檢索,但是並不要求所有文檔中的值域結構完全一樣。
對於搜索引擎來說,返回的結果文檔是按照得分做降序排列的,該得分表示文檔和查詢的匹配程度。匹配程度得分依據一系列的因子來計算,不過一般說來得分越高,表明結果文檔同查詢之間的相關度越高。如果要人工干預排序的結果,你可以給特定的文檔、值域、或者查詢字串增加權重,或著直接提高某個文檔的相關度分值。
在返回用戶最初的查詢所對應的文檔結果的同時,提供給用戶一個工具,使其能夠不斷地改進查詢以獲得更需要的信息。換句話說,在返回匹配的文檔之外,你應該返回一個工具讓用戶知道下一步該怎麼辦。舉個例子,你可以對查詢結果按照屬性進行分類,便於用戶根據需求做進一步的浏覽。這種功能稱之為分類檢索(Faceted-Search),這也是Solr的功能亮點之一。
對於一個查詢結果有好幾百萬個文檔的情況,如果你要求所有的匹配文檔都要能夠一次返回。那麼你會等待很長的時間。查詢本身會執行的很快,但是從索引結構中重建上百萬的文檔絕對是一件很耗時間的事情。因為Solr這樣的搜索引擎在硬盤上存儲值域的方式只適用於快速生成少量的文檔結果,如果需要一次生成大量的查詢結果,在這種存儲方式之下生成大量文檔結果就會耗費大量的時間。
另一個不適合應用搜索引擎的使用場景是需要讀取索引文件的大部分子集的才能完成的深度分析任務場景。即使你通過結果分頁技術避免了剛剛說的那個問題,如果一次分析需要讀取索引文件中的大量數據,你也會遇到很大的性能問題,因為索引文件的底層數據結構就不是為一次大量讀取來設計的。
搜索引擎技術並不適合用於在文檔的相互關系之間進行查詢。Solr確實是可以支持基於父子關系的查詢,但是並不支持在復雜的關系型數據結構之間查詢。
信息檢索(IR)是指從海量的數據集合(通常存儲在計算機系統中)中,根據某種非結構化的本質屬性(通常是文本內容)查找出滿足信息需求的材料(通常是文檔)的過程。
Lucene底層用JAVA實現倒排索引的建立和管理。倒排索引即倒排表,是用於匹配文本查詢的特殊數據結構。
雖然Lucene提供了建立文檔索引和執行查詢的核心架構,但它並沒有提供一個方便的接口來設置索引應該如何建立。要使用Lucene,你需要寫一些JAVA代碼來定義值域,還要定義如何分析這些值域。而Solr則提供了簡單的聲明方式來定義索引的結構,你也可以按照需求來指定如何分析索引中的值域。這一切都可以通過一個名叫schema.xml的XML配置文件來完成。Solr在其底層實現中將schema.xml中的配置翻譯成Lucene的index。
此外Solr在核心的Lucene索引功能之上還添加了其他一些不錯的功能。具體來說,Solr提供了Copy Fields和Dynamic Fields兩種新的值域類型。Copy Fields提供了一種方法,可以將一個或多個值域中的原始文本內容賦值到另一個新的field值域中。Dynamic Fields則允許你無須在schema.xml裡顯式的聲明,就可以將同一值域類型賦予多個不同的值域。
Solr作為一個Java web應用,既可以運行在任意一個現代JAVA Servlet引擎之上,比如Jetty或是Tomcat,也可以運行在JBoss或是Oracle AS之類的完整的J2EE應用服務器上。為了達到易於集成的目標,Solr的核心服務需要能夠被不同的應用和編程語言訪問。Solr提供簡單的類REST服務,支持XML,JSON,HTTP等標准。順便說一句,我們並不使用RESTFul一詞來描述Solr基於HTTP的API,因為它並不嚴格遵守所有的REST(Representatonal state transfer)原則。針對許多流行的編程語言,Solr都提供了相應的庫,包括Python,JAVA, .NET,還有Ruby等等。
Solr支持在單一的Solr引擎上運行多個Solr核心。每一個核心都有一個獨立的索引和配置,在一個Solr實例中可以存在多個Solr核心。這樣你只需要一個Solr服務器就可以管理多個核心,可以方便的實現服務器資源共享,以及及監控維護服務的共享。Solr有專門的API用於創建和管理多個Core。Solr多核心支持功能的一個應用是數據分區,比如用一個core來負責最近更新的文檔,而用另外的core來處理之前生成的文檔,這個功能被稱為按時間順序分片。
Solr種最主要的三個子系統:文檔管理,查詢處理,和文本分析。當然,這些子系統是對Solr中復雜的子系統所做的宏觀抽象,我們會在稍後的章節中一一研究這些子系統。這其中的每一個都是由一系列功能模塊的流水線串成的,你可以在流水線中串入新的功能模塊。這意味著如果你想給solr加入新的功能的話,根本不需要重寫整個查詢處理引擎,只需要在合適的位置串入自己的新功能模塊即可。這樣一來Solr的核心功能模塊擴展和定制起來都很方便,可以完全按照你的特定應用需求進行定制。
Solr實現可伸縮性的第一張牌是靈活的cache管理功能,該功能可以避免服務器重復進行耗費資源的操作。具體來說就是Solr預先設置了一些cache來節省開銷很大的重復計算,比如Solr會緩存查詢過濾器的計算結果。
緩存的作用是有限的,為了處理更多的文檔和獲得更高的查詢吞吐能力,你需要能夠通過擴展服務器來橫向擴展系統的性能。
Solr擴展時最常見的兩個方面:
第一個是查詢的吞吐能力擴展, 增加replicas,如果需要得到更高的查詢吞吐能力,你需要增加查詢服務器和索引的拷貝數量,以便讓更多的服務器來同時處理更多的請求。
另一個擴展維度是被索引的文檔數, 增加shards,把索引文件切分成一個個被稱為“分片”的小塊,然後把查詢請求分布到這些分片上進行操作。
給每一個shard增加replica,當某一個分片掛了,把所有請求都發到備份哪兒去。
主要從一下三類介紹一下
Solr提供了一系列的重要功能來幫助你搭建一個易用的,符合用戶直覺的,功能強大的搜索引擎。不過你需要注意的是Solr僅僅是提供了類REST風格的HTTP API接口,她並不提供搜索界面相關的UI組件和框架。
分頁和排序功能
Solr不會返回所有符合查詢條件的結果。Solr在分頁請求查詢結果方面做了優化,每次只有最靠前的N個文檔會被在請求第一頁結果時返回。如果用戶在第一頁結果中沒有找到想要的信息,那麼可以通過很簡單的API調用和請求參數獲得後續頁碼的內容。分頁功能對於兩類關鍵的輸出有幫助:1)結果返回的更快了,因為每次查詢都只需要返回整個搜索結果中的一個很小的集合;2)可以幫助你追蹤到底有多少請求是針對更多頁碼內容的。這個指標可以反映出你的相關性得分的計算是否有問題。
分類檢索功能
分類檢索功能將搜索結果按照特性分類放到一個個小組中,這就為為用戶提供了一個不斷優化搜索關鍵字和浏覽搜索結果的工具。其實就是導航功能。
自動補全功能
自動補全功能會根據系統索引文件中的文檔內容在用戶輸入關鍵詞的時候做出相應的自動填補建議。Solr的自動補全功能使得用戶只需要輸入少數幾個字符就能得到一個根據這些輸入字符推薦出來的查詢詞列表。這能大大降低用戶輸入錯誤查詢詞的幾率,尤其是現在很多用戶都會在移動設備上用小鍵盤輸入搜索內容。
拼寫檢查功能
用戶在輸入帶有拼寫錯誤的查詢詞時,仍然會期待搜索引擎能夠優雅的自動處理掉這些小錯誤,返回給用戶正確的查詢結果。Solr的拼寫檢查支持兩種基本的模式:
自動糾錯模式:Solr可以在用戶出現拼寫錯誤的時候自動根據該詞語在索引中是否存在而做出相應的糾錯處理
”您要找的是不是…“功能:Solr也可以根據用戶的輸入,為用戶建議一個更佳的輸入方案,比如當用戶輸入”hilands“時,solr會建議用戶”您要找的是不是highlands?“
高亮命中結果功能
在搜索文本量比較大的文檔時,你可以通過Solr的高亮命中結果功能對命中的內容進行高亮顯示。這在文本內容很長的文檔中很實用,用戶可以借此功能很方便的在長長的文本內容中一眼找到命中的搜索內容部分。
地理位置查詢功能
地理位置搜索是Solr 4中的一個很棒的功能,Solr 4自建了對經度值和緯度值的索引支持,可以對文檔按照地理位置的遠近做出排序。Solr可以根據到地理位置上某一點(某一具體的經度和緯度上的一點)的距離,查找出相應的文檔記錄並對結果排序。 Solr 4中另一個激動人心的功能是你甚至可以通過在地圖上畫出各種幾何圖形,比如多邊形,根據不同形狀之間的交集來做地理位置查詢。
值域的合並和分組功能
雖然Solr要求處理的文檔盡量的扁平化、非規格化,但還是允許你將多個文檔按照大家共有的某種屬性進行歸組管理。值域分組,也被稱為值域的合並,允許你在返回結果時除了可以返回一個個的文檔之外還可以返回一個特定的文檔分組。
靈活的查詢支持功能
Solr提供了一系列強大的查詢功能,包括:
連接功能
但是在Solr中,join操作更像是SQL中的子查詢,只是你並不會通過鏈接文檔之間的數據而創建新的文檔。例如,通過Solr的join功能,你可以返回父文檔符合查詢條件的子文檔。Solr連接功能在你需要拿到某條推特或是微博的所有評論時很有用,所有評論都是原文的子文檔。
歸集功能
文檔歸集功能允許可以根據每個文檔的描述將相似的文檔歸為一組。這有助於避免在返回查詢結果時返回很多內容很近似的文檔結果。例如,如果你的搜索引擎是一個新聞應用,通過多個RSS鏈接來推送文章,那麼你很可能會同時收到很多關於同一條新聞的報道。把這些內容差不多的報道都返回給用戶顯然不是一個好主意,此時你可以使用文檔歸集功能把這些類似的報導分成一組,選取一篇有代表性的報道返回給用戶就妥了。
從PDF和word等格式的文檔中導入富媒體數據的功能
在某些場合下,你可能需要處理一些已有的通用格式文檔,比如PDF和微軟word文檔之類的,你需要這些文檔也能被檢索。用Solr的話要實現這一點很簡單,因為Solr直接集成了Apache Tika項目,該項目幾乎支持所有的流行文檔格式。
從關系型數據庫中導入數據的功能
如果你想要搜索的數據是存儲在傳統的關系型數據庫當中的,那你可以配置Solr來通過SQL查詢語句創建文檔。
多種語言的支持
Solr和Lucene對多語言環境的支持已經發展了很長一段時間了。Solr內建了一個語言自動檢測系統,對多種不同的語言環境都提供特定語言的文本分析方案支持。
幾乎實時的搜索查詢
Solr的近乎實時(NRT)查詢功能支持應用在索引建立之後幾秒鐘就可以查詢到新加入的文本。所以利用NRT功能,Solr完全可以應付內容更新會很快的場景,比如頭條新聞或是社交網絡之類的應用。
支持樂觀並發機制的原子更新
原子更新功能允許客戶端應用可以對現有文檔的值域做添加、更新、刪除或是增加等操作而並不用重新發送整個文檔給Solr。
如果兩個不同的客戶端用戶試圖同時更新同一條文檔記錄時會怎麼樣。在這種情況下,Solr會使用樂觀並發機制來避免會產生沖突的更新。簡言之,Solr會用一個特定的叫做_Version_的值域來加強文檔更新過程中的安全性。當兩個不同用戶試圖同時更新同一文檔時,最後提交更新的用戶會得到過期版本的數據,所以其更新請求會失敗。
實時獲取功能
Solr也屬於NoSQL技術的一種。Solr的實時獲取功能絕對符合典型的NoSQL方式,它可以讓你通過文檔的唯一標識獲得最新版本的文檔內容,完全不需要考慮新版本的文檔內容是否提交到了索引當中。而在Solr 4版本之前,文本內容必須先要提交到Lucene索引文件中之後才能夠被訪問到。而利用Solr4的實時獲取功能,通過唯一標識獲取文檔內容的過程已經安全的同建立Lucene索引的過程分離開了。這在索引已經建立之後對文檔內容進行更新的時候很有用,不用再重新提交文檔內容建立新的索引了。
事務日志的持久層寫入
當一個文檔被發送到Solr進行索引的建立時,其內容會被寫入到一個事務日志中,以避免因為server故障而產生數據的丟失。Solr的事務日志處於從客戶端應用發送文檔過來,到把文檔內容提交到Lucene索引文件之間的一個中間狀態。它也參與實時獲取功能的實現,因為不管文檔是否已經提交到了Lucene索引文件中,其內容都可以通過唯一標識提取出來。
事務日志使得Solr可以將更新內容的持久化和更新內容的可見性分離開來。這意味著文檔可能會存在於持久化存儲中但是在搜索結果中並不可見。你自己的應用可以靈活控制何時將新的文檔內容提交到索引中從而使得新文檔內容在搜索時可以被檢索到。而你並不用擔心如果服務器在你提交索引之前掛掉的話新文檔內容會丟失的問題。
使用Zookeeper輕松的進行分片操作和復制操作
有了SolrCloud之後,橫向擴展變得很簡單而且自動化了。因為solr使用了Apache Zookeeper來同步配置和管理主分片及分片的復制備份。在Apache的官方網站上是這樣描述Zookeeper的:”這是一個用於維護配置信息,命名,提供分布式同步和分組服務的中心服務“。
在Solr中,Zookeeper負責指定主分片和分片的復制備份,並且負責監控服務器是否可以正常的響應查詢請求。SolrCloud已經綁定了Zookeeper服務,所以你不需要再做額外的配置就可以啟動SolrCloud。
 Android仿天天動聽歌曲自動滾動view
Android仿天天動聽歌曲自動滾動view
最近項目中要做一個類似天天動聽歌曲自動滾動行數的效果。首先自己想了下Android要滾動的那就是scroller類或者scrollto、scrollby結合了,或者vie
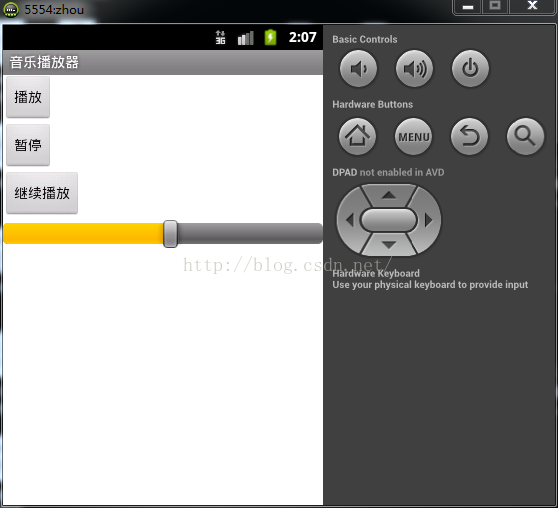 音樂播放器
音樂播放器
一、---框架---(1)新建布局,包括三個按鈕:播放、暫停、繼續播放,還有一個進度條(2)建立一個Service,其中有播放、暫停、繼續播放的方法(3)因為有進度條,所
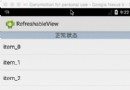 Android控件RefreshableView實現下拉刷新
Android控件RefreshableView實現下拉刷新
需求:自定義一個ViewGroup,實現可以下拉刷新的功能。下拉一定距離後(下拉時顯示的界面可以自定義任何復雜的界面)釋放手指可以回調刷新的功能,用戶處理完刷新的內容後,
 10個你可能不知道的 Android Studio技巧
10個你可能不知道的 Android Studio技巧
寫代碼的時候過度依賴鼠標可能會遇到比低效率更嚴重的問題。這裡的技巧幫助你寫更少的代碼,充分發揮鍵盤的功能,因此你可以避免發生這樣的情況:hanks Obama.這裡的絕大