編輯:關於Android編程
這幾天打算看下安卓的代碼,看優秀的源碼也是一種學習過程,看源碼的過程就感覺到,安卓確實是深受linux內核的影響,不少數據結構的用法完全一致。花了一中午時間,研究了下init.rc解析過程,做個記錄。
init.rc 文件並不是普通的配置文件,而是由一種被稱為“Android初始化語言”(Android Init Language,這裡簡稱為AIL)的腳本寫成的文件。在了解init如何解析init.rc文件之前,先了解AIL非常必要,否則機械地分析 init.c及其相關文件的源代碼毫無意義。
為了學習AIL,讀者可以到自己Android手機的根目錄尋找init.rc文件,最好下載到本地以便查看,如果有編譯好的Android源代碼, 在out/target/product/generic/root目錄也可找到init.rc文件。
AIL由如下4部分組成。
1. 動作(Actions)
2. 命令(Commands)
3. 服務(Services)
4. 選項(Options)
這4部分都是面向行的代碼,也就是說用回車換行符作為每一條語句的分隔符。而每一行的代碼由多個符號(Tokens)表示。可以使用反斜槓轉義符在 Token中插入空格。雙引號可以將多個由空格分隔的Tokens合成一個Tokens。如果一行寫不下,可以在行尾加上反斜槓,來連接下一行。也就是 說,可以用反斜槓將多行代碼連接成一行代碼。
AIL的注釋與很多Shell腳本一行,以#開頭。
AIL在編寫時需要分成多個部分(Section),而每一部分的開頭需要指定Actions或Services。也就是說,每一個Actions或 Services確定一個Section。而所有的Commands和Options只能屬於最近定義的Section。如果Commands和 Options在第一個Section之前被定義,它們將被忽略。
Actions和Services的名稱必須唯一。如果有兩個或多個Action或Service擁有同樣的名稱,那麼init在執行它們時將拋出錯誤,並忽略這些Action和Service。
下面來看看Actions、Services、Commands和Options分別應如何設置。
Actions的語法格式如下:
on
on boot
ifup lo
hostname localhost
domainname localdomain
service[ ]*
service servicemanager /system/bin/servicemanager
class core
user system
group system
critical
onrestart restart zygote
onrestart restart media
onrestart restart surfaceflinger
onrestart restart drm 現在接著分析一下init是如何解析init.rc的。現在打開system/core/init/init.c文件,找到main函數。在上一篇文章中 分析了main函數的前一部分(初始化屬性、處理內核命令行等),現在找到init_parse_config_file函數,調用代碼如下:
init_parse_config_file("/init.rc");
這個方法主要負責初始化和分析init.rc文件。init_parse_config_file函數在init_parser.c文件中實現,代碼如下:
int init_parse_config_file(const char *fn)
{
char *data;
data = read_file(fn, 0);
if (!data) return -1;
/* 實際分析init.rc文件的代碼 */
parse_config(fn, data);
DUMP();
return 0;
}
static void parse_config(const char *fn, char *s)
{
struct parse_state state;
struct listnode import_list;
struct listnode *node;
char *args[INIT_PARSER_MAXARGS];
int nargs;
nargs = 0;
state.filename = fn;
state.line = 0;
state.ptr = s;
state.nexttoken = 0;
state.parse_line = parse_line_no_op;
list_init(&import_list);
state.priv = &import_list;
/* 開始獲取每一個token,然後分析這些token,每一個token就是有空格、字表符和回車符分隔的字符串
*/
for (;;) {
/* next_token函數相當於詞法分析器 */
switch (next_token(&state)) {
case T_EOF: /* init.rc文件分析完畢 */
state.parse_line(&state, 0, 0);
goto parser_done;
case T_NEWLINE: /* 分析每一行的命令 */
/* 下面的代碼相當於語法分析器 */
state.line++;
if (nargs) {
int kw = lookup_keyword(args[0]);
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;
}
break;
case T_TEXT: /* 處理每一個token */
if (nargs < INIT_PARSER_MAXARGS) {
args[nargs++] = state.text;
}
break;
}
}
parser_done:
/* 最後處理由import導入的初始化文件 */
list_for_each(node, &import_list) {
struct import *import = node_to_item(node, struct import, list);
int ret;
INFO("importing '%s'", import->filename);
/* 遞歸調用 */
ret = init_parse_config_file(import->filename);
if (ret)
ERROR("could not import file '%s' from '%s'\n",
import->filename, fn);
}
} for循環中調用next_token不斷從init.rc文件中獲取token,這裡的token,就是一種編程語言的最小單位,也就是不可再分。例如,對於傳統的編程語言的if、then等關鍵字、變量名等標識符都屬於一個token。而對於init.rc文件來說,import、on以及觸發器的參數值都是屬於一個token。一個解析器要進行語法和詞法的分析,詞法分析就是在文件中找出一個個的token,也就是說,詞法分析器的返回值是token,而語法分析器的輸入就是詞法分析器的輸出。也就是說,語法分析器就需要分析一個個的token,而不是一個個的字符。詞法分析器就是next_token,而語法分析器就是T_NEWLINE分支中的代碼。下面我們來看看next_token是怎麼獲取一個個的token的。
int next_token(struct parse_state *state)
{
char *x = state->ptr;
char *s;
if (state->nexttoken) {
int t = state->nexttoken;
state->nexttoken = 0;
return t;
}
/* 在這裡開始一個字符一個字符地分析 */
for (;;) {
switch (*x) {
case 0:
state->ptr = x;
return T_EOF;
case '\n':
x++;
state->ptr = x;
return T_NEWLINE;
case ' ':
case '\t':
case '\r':
x++;
continue;
case '#':
while (*x && (*x != '\n')) x++;
if (*x == '\n') {
state->ptr = x+1;
return T_NEWLINE;
} else {
state->ptr = x;
return T_EOF;
}
default:
goto text;
}
}
textdone:
state->ptr = x;
*s = 0;
return T_TEXT;
text:
state->text = s = x;
textresume:
for (;;) {
switch (*x) {
case 0:
goto textdone;
case ' ':
case '\t':
case '\r':
x++;
goto textdone;
case '\n':
state->nexttoken = T_NEWLINE;
x++;
goto textdone;
case '"':
x++;
for (;;) {
switch (*x) {
case 0:
/* unterminated quoted thing */
state->ptr = x;
return T_EOF;
case '"':
x++;
goto textresume;
default:
*s++ = *x++;
}
}
break;
case '\\':
x++;
switch (*x) {
case 0:
goto textdone;
case 'n':
*s++ = '\n';
break;
case 'r':
*s++ = '\r';
break;
case 't':
*s++ = '\t';
break;
case '\\':
*s++ = '\\';
break;
case '\r':
/* \ -> line continuation */
if (x[1] != '\n') {
x++;
continue;
}
case '\n':
/* \ -> line continuation */
state->line++;
x++;
/* eat any extra whitespace */
while((*x == ' ') || (*x == '\t')) x++;
continue;
default:
/* unknown escape -- just copy */
*s++ = *x++;
}
continue;
default:
*s++ = *x++;
}
}
return T_EOF;
} next_token的代碼還是蠻多的,不過原理到很簡單。就是逐一讀取init.rc文件的字符,並將由空格、/t分隔的字符串挑出來,並通過state_text返回,並通過state->text返回。如果返回正常的token,next_token就返回T_TEXT。如果一行結束,就返回T_NEWLINE,並開始語法分析,特別注意:init初始化語言是基於行的,所以語言分析實際上就是分析init.rc的每一行,只是這些行已經被分解成一個個的token並保存在args數組當中。現在來回顧一下T_NEWLINE分支的完整代碼
case T_NEWLINE:
state.line++;
if (nargs) {
int kw = lookup_keyword(args[0]);
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;
}
break;上面的代碼首先調用lookup_keyword搜索關鍵字,該方法的作用是判定當前行是否合法:也就是根據init初始化預定義的關鍵字查詢,如果沒有查到返回K_UNKNOWN。如果當前行合法,則會執行parse_new_section函數,該函數將為section和action設置處理函數。代碼如下:void parse_new_section(struct parse_state *state, int kw,
int nargs, char **args)
{
printf("[ %s %s ]\n", args[0],
nargs > 1 ? args[1] : "");
switch(kw) {
case K_service: // 處理service
state->context = parse_service(state, nargs, args);
if (state->context) {
state->parse_line = parse_line_service;
return;
}
break;
case K_on: // 處理action
state->context = parse_action(state, nargs, args);
if (state->context) {
state->parse_line = parse_line_action;
return;
}
break;
case K_import: // 單獨處理import導入的初始化文件。
parse_import(state, nargs, args);
break;
}
state->parse_line = parse_line_no_op;
} 我們拿case K_service舉例:首先調用parse_service函數,該函數代碼如下:
static void *parse_service(struct parse_state *state, int nargs, char **args)
{
struct service *svc;
if (nargs < 3) {
parse_error(state, "services must have a name and a program\n");
return 0;
}
if (!valid_name(args[1])) {
parse_error(state, "invalid service name '%s'\n", args[1]);
return 0;
}
svc = service_find_by_name(args[1]);
if (svc) {
parse_error(state, "ignored duplicate definition of service '%s'\n", args[1]);
return 0;
}
nargs -= 2;
svc = calloc(1, sizeof(*svc) + sizeof(char*) * nargs);
if (!svc) {
parse_error(state, "out of memory\n");
return 0;
}
svc->name = args[1];
svc->classname = "default";
memcpy(svc->args, args + 2, sizeof(char*) * nargs);
svc->args[nargs] = 0;
svc->nargs = nargs;
svc->onrestart.name = "onrestart";
list_init(&svc->onrestart.commands);
list_add_tail(&service_list, &svc->slist);
return svc;
}該函數先判定當前行參數個數,比如service daemon /system/bin/daemon,此時剛好滿足條件,參數剛剛是三個,第一個是service關鍵字,第二個參數是服務名,第三個參數是服務所在的路徑。然後調用service_find_by_name在serivce_list隊列查找當前行的服務是否已經添加過隊列,如果添加過即svc!=NULL,那麼就報錯;最後最重要的一點,填充svc結構體的內容,並將其添加到service_list雙向鏈表當中。在填充結構體的內容的時候需要注意的點是:srv->args[]數組的內容,只保存參數,什麼意思呢?舉個例子,比如init.rc中有這麼一行代碼:service
dumpstate /system/bin/dumpstate -s,那麼剛進入到parse_service函數的時候,nargs=4。但是svc的args數組只需要保存/system/bin/dumpstate -s這兩個參數就好了!!
然後會重新設置state->parse_line,比如對於service的section解析來說,state->parse_line = parse_line_service;這樣就會調用parse_line_service解析services的options。
 最佳實踐之 Android代碼規范
最佳實踐之 Android代碼規范
命名規范包命名規范采用反域名命名規則,包名全部小寫,連續的單詞只是簡單地連接起來,不使用下劃線,一級包名為com,二級包名為xxx(可以是公司域名或者個人命名),三級包名
 微信ohh是什麼意思 微信翻譯有趣表白代碼都有哪些
微信ohh是什麼意思 微信翻譯有趣表白代碼都有哪些
微信ohh是什麼意思?在微信聊天及朋友圈那裡都可以看到,小伙伴們在微信中輸入ohh,然後叫別人使用微信翻譯來翻譯這個詞會出現“留在我身邊&rdq
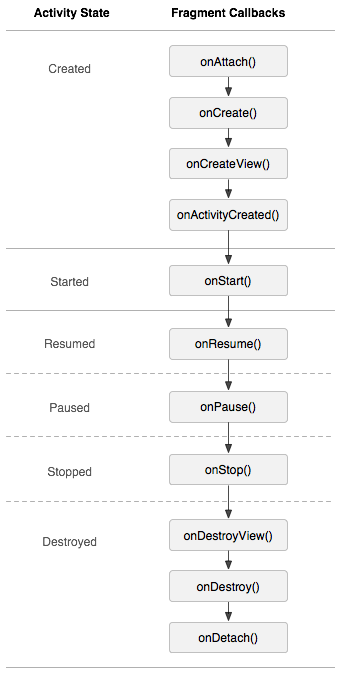 Fragment介紹及兩種使用方法
Fragment介紹及兩種使用方法
為何產生同時適配手機和平板、UI和邏輯的共享。介紹Fragment也會被加入回退棧中。Fragment擁有自己的生命周期和接受、處理用戶的事件可以動態的添加、替換和移除某
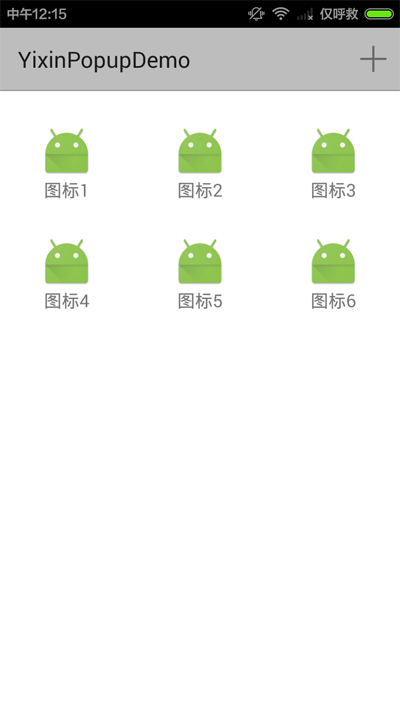 Android編程實現仿易信精美彈出框效果【附demo源碼下載】
Android編程實現仿易信精美彈出框效果【附demo源碼下載】
本文實例講述了Android編程實現仿易信精美彈出框效果。分享給大家供大家參考,具體如下:截圖:動畫效果介紹:1.點擊ActionBar上“+”按鈕,菜單從上方彈出(帶反