編輯:關於Android編程
Android4.4 GUI系統框架之SurfaceFlinger
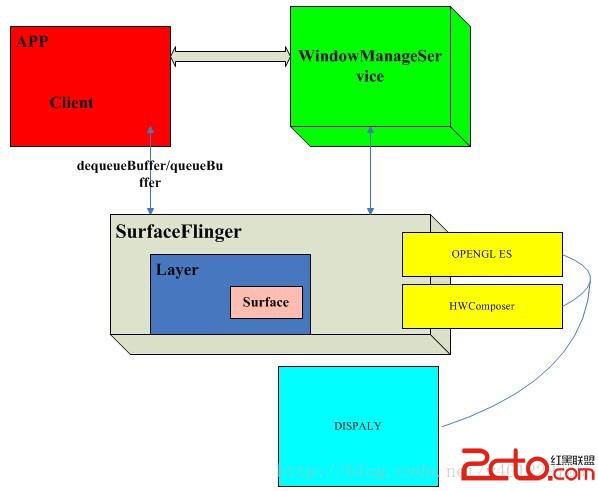
SurfaceFlinger:每當用戶程序刷新UI的時候,會中介BufferQueue申請一個buffer(dequeueBuffer),然後把UI的信息填入,丟給SurfaceFlinger,SurfaceFlinger通過計算多重計算合成visibleRegion之後,丟給openGL層處理,處理之後送到顯示器display上顯示。
根據整個Android系統的GUI設計理念,我們不難猜想到至少需要兩種本地窗口:
? 面向管理者(SurfaceFlinger)
既然SurfaceFlinger扮演了系統中所有UI界面的管理者,那麼它無可厚非地需要直接或間接地持有“本地窗口”,這個窗口就是FramebufferNativeWindow
? 面向應用程序
這類窗口是Surface(這裡和以前版本出入比較大,之前的版本本地窗口是SurfaceTextureClient)
第二種窗口是能直接顯示在終端屏幕上的——它使用了幀緩沖區,而第一種Window實際上是從內存緩沖區分配的空間。當系統中存在多個應用程序時,這能保證它們都可以獲得一個“本地窗口”,並且這些窗口最終也能顯示到屏幕上——SurfaceFlinger會收集所有程序的顯示需求,對它們做統一的圖像混合操作。
一個UI完全顯示到diplay的過程,SurfaceFlinger扮演著重要的角色但是它的職責是“Flinger”,即把系統中所有應用程序的最終的“繪圖結果”進行“混合”,然後統一顯示到物理屏幕上,而其他方面比如各個程序的繪畫過程,就由其他東西來擔任了。這個光榮的任務自然而然地落在了BufferQueue的肩膀上,它是每個應用程序“一對一”的輔導老師,指導著UI程序的“畫板申請”、“作畫流程”等一系列細節。下面的圖描述了這三者的關系:
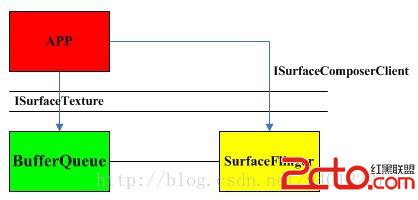
雖說是三者的關系,但是他們所屬的層卻只有兩個,app屬於java層,BufferQueue/SurfaceFlinger屬於native層。也就是說BufferQueue也是隸屬SurfaceFlinger,所有工作圍繞SurfaceFlinger展開。
這裡IGraphicBufferProducer就是app和BufferQueue重要橋梁,GraphicBufferProducer承擔著單個應用進程中的UI顯示需求,與BufferQueue打交道的就是它。它的工作流程如下:
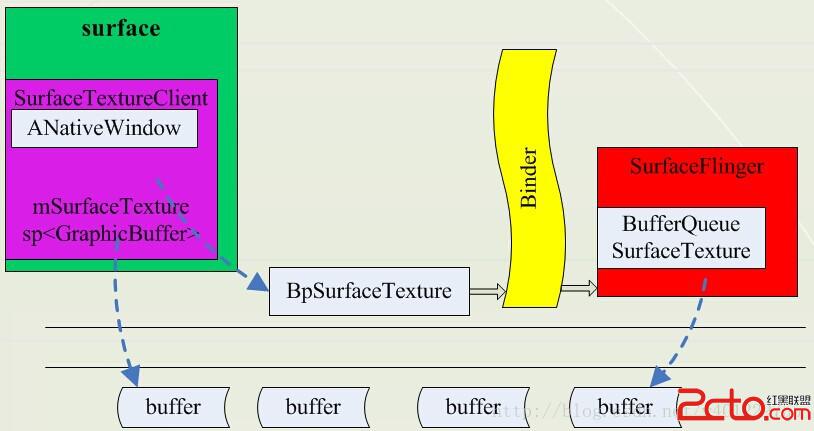
BpGraphicBufferProducer是GraphicBufferProducer在客戶端這邊的代理對象,負責和SF交互,GraphicBufferProducer通過gbp(IGraphicBufferProducer類對象)向BufferQueue獲取buffer,然後進行填充UI信息,當填充完畢會通知SF,SF知道後就對該Buffer進行下一步操作。典型的生產-消費者模式。
接下來具體說明客戶端(producer)和服務端SurfaceFlinger(consumer)工作的模式:
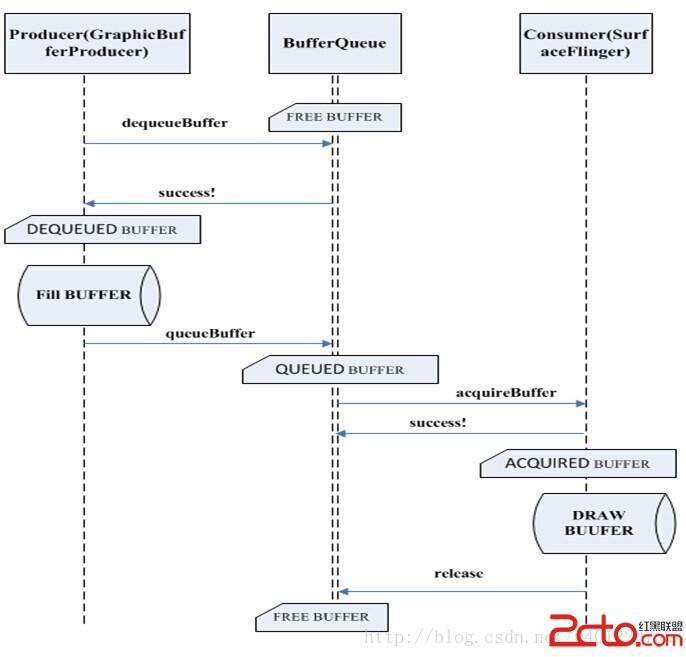
首先這裡的buffer是共享緩沖區,故肯定會涉及到互斥鎖,所以buffer的狀態也會有多種,一般的buffer大致會經過FREE->DEQUEUED->QUEUED->ACQUIRED->FREE這個流程,如右圖:
? BufferQueue
可以認為BufferQueue是一個服務中心,其它兩個owner必須要通過它來管理buffer。比如說當producer想要獲取一個buffer時,它不能越過BufferQueue直接與consumer進行聯系,反之亦然。
? Producer
生產者就是“填充”buffer空間的人,通常情況下當然就是應用程序。因為應用程序不斷地刷新UI,從而將產生的顯示數據源源不斷地寫到buffer中。當Producer需要使用一塊buffer時,它首先會向中介BufferQueue發起dequeue申請,然後才能對指定的緩沖區進行操作。這種情況下buffer就屬於producer一個人的了,它可以對buffer進行任何必要的操作,而其它owner此刻絕不能擅自插手。
當生產者認為一塊buffer已經寫入完成後,它進一步調用BufferQueue的queue。從字面上看這個函數是“入列”的意思,形象地表達了buffer此時的操作——把buffer歸還到BufferQueue的隊列中。一旦queue成功後,owner也就隨之改變為BufferQueue了
? Consumer
消費者是與生產者相對應的,它的操作同樣受到BufferQueue的管控。當一塊buffer已經就緒後,Consumer就可以開始工作了。這裡需要特別留意的是,從各個對象所扮演的角色來看,BufferQueue是中介機構,屬於服務提供方;Producer屬於buffer內容的產出方,它對緩沖區的操作是一個“主動”的過程;反之,Consumer對buffer的處理則是“被動”的、“等待式”的——它必須要等到一塊buffer填充完成後才能做工作。在這樣的模型下,我們怎麼保證Consumer可以及時的處理buffer呢?換句話說,當一塊buffer數據ready後,應該怎麼告知Consumer來操作呢?
仔細觀察的話,可以看到BufferQueue裡還同時提供了一個特別的類,名稱為ProxyConsumerListener,其中的函數接口包括:
classProxyConsumerListener : public BnConsumerListener {
public:
//省略構造函數
virtual void onFrameAvailable();/*當一塊buffer可以被消費時,這個函數會被調用,特別注意此時沒有共享鎖的保護*/
virtual voidonBuffersReleased();/*BufferQueue通知consumer它已經釋放其slot中的一個或多個 GraphicBuffer引用*/
private:
wpmConsumerListener;
}
這樣子就很清楚了,當有一幀數據准備就緒後,BufferQueue就會調用onFrameAvailable()來通知Consumer進行消費。
BufferQueue和SurfaceFlinger之間的通信模式如下:

也是有一對BpGraphicBufferConsumer/BnGraphicBufferConsumer支持他們之間的信息傳輸。
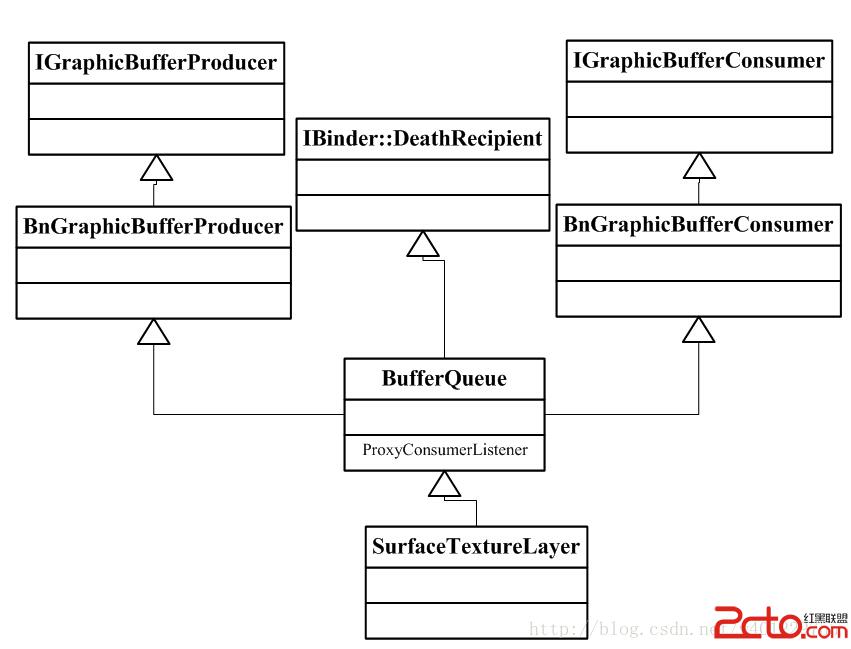
首先說明一下BufferQueue的類關系:
下面是BufferQueue中的核心函數分析:
核心成員函數
說明
setBufferCount
setBufferCount updates the number of available buffer slots.
requestBuffer
requestBuffer returns the GraphicBuffer for slot N.
dequeueBuffer
dequeueBuffer gets the next buffer slot index for the producer to use.
queueBuffer
queueBuffer returns a filled buffer to the BufferQueue.
cancelBuffer
cancelBuffer returns a dequeued buffer to the BufferQueue
acquireBuffer
acquireBuffer attempts to acquire ownership of the next pending buffer BufferQueue.
releaseBuffer
releaseBuffer releases a buffer slot from the consumer back to the BufferQueue.
BufferQueue是IGraphicBufferProducer和IGraphicBufferConsumer的具體實現,用戶在請求和SurfaceFlinger連接的過程中會請求SF創建一個Layer,IGraphicBufferProducer就是在這個過程中獲取一個BufferQueue對象,又轉化成IGraphicBufferProducer類對象,是為了進一步和BufferQueue進行交互,下面是關鍵代碼:
status_t SurfaceFlinger::createNormalLayer(constsp& client, const String8& name, uint32_t w,uint32_t h, uint32_t flags, PixelFormat& format, sp * handle, sp *gbpsp * outLayer) { switch (format) { case PIXEL_FORMAT_TRANSPARENT: case PIXEL_FORMAT_TRANSLUCENT: format = PIXEL_FORMAT_RGBA_8888; break; case PIXEL_FORMAT_OPAQUE: } #ifdefNO_RGBX_8888 if (format == PIXEL_FORMAT_RGBX_8888) format = PIXEL_FORMAT_RGBA_8888; #endif *outLayer = new Layer(this, client, name,w, h, flags); status_t err =(*outLayer)->setBuffers(w, h, format, flags); if (err == NO_ERROR) { *handle = (*outLayer)->getHandle(); *gbp =(*outLayer)->getBufferQueue(); } ALOGE_IF(err, "createNormalLayer()failed (%s)", strerror(-err)); return err; }
下面是getBufferQueue的實現,很簡單,獲取BufferQueue對象:
spLayer::getBufferQueue() const { return mBufferQueue; }
IGraphicBufferProducer是個接口類,它的實現必然在子類BpGraphicBufferProducer中實現,我們來看下這個類:
classBpGraphicBufferProducer : public BpInterface{ public: BpGraphicBufferProducer(constsp & impl) :BpInterface (impl) { } virtual status_t requestBuffer(intbufferIdx, sp * buf) { Parcel data, reply; data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor()); data.writeInt32(bufferIdx); status_t result =remote()->transact(REQUEST_BUFFER, data,&reply); if (result != NO_ERROR) { return result; } bool nonNull = reply.readInt32(); if (nonNull) { *buf = new GraphicBuffer(); reply.read(**buf); } result = reply.readInt32(); return result; } virtual status_t dequeueBuffer(int*buf, sp * fence, bool async, uint32_t w, uint32_t h, uint32_tformat, uint32_t usage) { Parcel data, reply; data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor()); data.writeInt32(async); data.writeInt32(w); data.writeInt32(h); data.writeInt32(format); data.writeInt32(usage); status_t result = remote()->transact(DEQUEUE_BUFFER, data,&reply); if (result != NO_ERROR) { return result; } *buf = reply.readInt32(); bool nonNull = reply.readInt32(); if (nonNull) { *fence = new Fence(); reply.read(**fence); } result = reply.readInt32(); return result; } virtual status_t queueBuffer(intbuf, const QueueBufferInput& input,QueueBufferOutput* output) { Parcel data, reply; data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor()); data.writeInt32(buf); data.write(input); status_t result = remote()->transactQUEUE_BUFFER, data, &reply); if (result != NO_ERROR) { return result; } memcpy(output,reply.readInplace(sizeof(*output)), sizeof(*output)); result = reply.readInt32(); return result;
省去了一些成員函數,只貼出關鍵成員函數,首先這裡的dequeueBuffer和queueBuffer並非真正對Buffer進行操作,留意紅色部分,會發現他只是發出一個“消息”通知接收方要去
Dequeue一個Buffer或queue一個Buffer。相對應的BnGraphicBufferProducer來接收消息。
BnGraphicBufferProducer中的onTransact負責這件事:
status_tBnGraphicBufferProducer::onTransact(
uint32_t code, const Parcel& data,Parcel* reply, uint32_t flags)
{
switch(code) {
case DEQUEUE_BUFFER: {
CHECK_INTERFACE(IGraphicBufferProducer, data, reply);
bool async = data.readInt32();
uint32_t w = data.readInt32();
uint32_t h =data.readInt32();
uint32_t format = data.readInt32();
uint32_t usage = data.readInt32();
int buf;
sp fence;
int result = dequeueBuffer(&buf, &fence, async, w, h,format, usage);
reply->writeInt32(buf);
reply->writeInt32(fence !=NULL);
if (fence != NULL) {
reply->write(*fence);
}
reply->writeInt32(result);
return NO_ERROR;
} break;
case QUEUE_BUFFER: {
CHECK_INTERFACE(IGraphicBufferProducer, data, reply);
int buf = data.readInt32();
QueueBufferInput input(data);
QueueBufferOutput* const output =
reinterpret_cast(
reply->writeInplace(sizeof(QueueBufferOutput)));
status_t result = queueBuffer(buf, input, output);
reply->writeInt32(result);
return NO_ERROR;
} break;
}
return BBinder::onTransact(code, data,reply, flags);
}
省略了一些分支,留意紅色部分才發現這裡調用了dequeueBuffer和queueBuffer,
它們的實現在BufferQueue中,這裡才真正踏足到BufferQueue領域中。到這裡客戶端和BufferQueue建立聯系,接下去的事就是BufferQueue內部處理的事了,BufferQueue和SuefaceFlinger之間的關系也如此。
這裡先用2張圖來介紹下SurfaceFlinger的整個消息處理機制和工作流程:
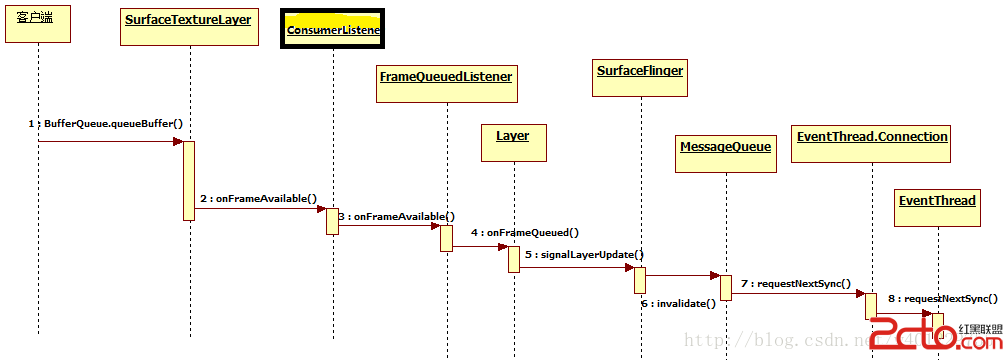
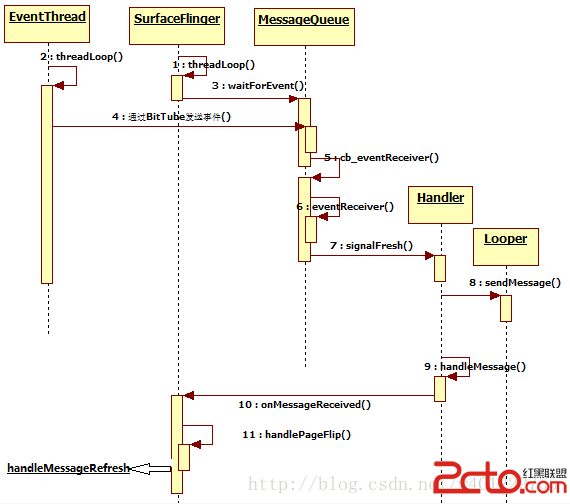
更具體的代碼流程之前有經過分析。
這裡繼續下去對handleMessageRefresh分析,這是SuefaceFlinger的核心處理函數。
voidSurfaceFlinger::handleMessageRefresh() {
ATRACE_CALL();
preComposition();
rebuildLayerStacks();
setUpHWComposer();
doDebugFlashRegions();
doComposition();
postComposition();
//………省略
}
preComposition();預先准備“合成物“就是客戶端那邊傳來的UI信息的buffer;
rebuildLayerStacks();在每一個screen上重建可見區域;
setUpHWComposer();初始化一個硬件容器;
doDebugFlashRegions();這個函數一般進去就返回來了;
doComposition();實質的合成過程,並且合成完的BUFFER由opengl es處理,處理之後由postFramebuffer()送到display上顯示;
這裡重點研究doComposition()
voidSurfaceFlinger::doComposition() {
ATRACE_CALL();
const bool repaintEverything =android_atomic_and(0, &mRepaintEverything);
for (size_t dpy=0 ; dpy&hw(mDisplays[dpy]);
if (hw->canDraw()) {
// transform the dirty region intothis screen's coordinate space
const Region dirtyRegion(hw->getDirtyRegion(repaintEverything));
// repaint the framebuffer (ifneeded)
doDisplayComposition(hw, dirtyRegion);
hw->dirtyRegion.clear();
hw->flip(hw->swapRegion);
hw->swapRegion.clear();
}
// inform the h/w that we're donecompositing
hw->compositionComplete();
}
postFramebuffer();
}
doDisplayComposition(hw, dirtyRegion);負責渲染的核心函數它的走向是:
doDisplayComposition-> doComposeSurfaces->draw->onDraw->drawWithOpenGL.一直走到OPENGL層。Opengl貼完圖之後,調用了flip函數,在這裡跟之前版本有很大出入,之前版本flip是在postFramebuffer中的,而且函數內容也做了很大的改變,只是計數加一。
在這裡說明一下,UI顯示是雙緩沖機制,每當畫完一個buffer需要flip一下,也就是交換。但在這個版本已經融合到postFramebuffer中:
貼出關鍵代碼
r = hwc.commit();
成員變量hwc是在DisplayHardware::init中生成的一個HWComposer對象。只要HWC_HARDWARE_MODULE_ID模塊可以正常加載,且hwc_open能打開hwc_composer_device設備,那麼initCheck()就返回NO_ERROR,否則就是NO_INIT。
此時我們通過HWComposer::commit來執行flip,這個函數直接調用如下硬件接口:
mHwc->set(mHwc, mNumDisplays, mLists);
set()和後面的eglSwapBuffers是基本等價的,原型如下:
int (*set)(struct hwc_composer_device*dev,hwc_display_t dpy,
hwc_layer_list_t* list);
其中最後一個list必須與最近一次的prepare()所用列表完全一致。假如list為空或者列表數量為0的話,說明SurfaceFlinger已經利用OpenGL ES做了composition,此時set就和eglSwapBuffers一樣。當list不為空,且layer的compositionType == HWC_OVERLAY,那麼HWComposer需要進行硬件合成。
如果成功執行的話,set返回0,否則就是HWC_EGL_ERROR。
如果沒成功的話,後面還有一句:
if (r)
{
hw->hwcSwapBuffers();
}
作用也是跟flip一樣。它的函數走向是:
hwcSwapBuffers->eglSwapBuffers->swapBuffers->advanceFrame-> fbPost->post。
一旦交換完畢就順著這個走向拋給底層display去顯示。
這裡我們主要研究swapBuffers這個函數:
EGLBooleanegl_window_surface_v2_t::swapBuffers()
{
//………….
nativeWindow->queueBuffer(nativeWindow,buffer, -1);
// dequeue a new buffer
if (nativeWindow->dequeueBuffer(nativeWindow, &buffer, &fenceFd)== NO_ERROR) {
sp fence(new Fence(fenceFd));
if(fence->wait(Fence::TIMEOUT_NEVER)) {
nativeWindow->cancelBuffer(nativeWindow, buffer, fenceFd);
return setError(EGL_BAD_ALLOC,EGL_FALSE);
}
//。。。。。。
}
這和我一開始的那張圖的流程是一致的——通過queueBuffer來入隊,然後通過dequeueBuffer重新申請一個buffer以用於下一輪的刷新。
 Android開發之內存管理
Android開發之內存管理
概念應用的開發離不開存儲,存儲分為網絡、內存、SDCard文件存儲以及外部SDCard2文件存儲,開發中一定要注意好內存管理以免oom、卡頓等不好的用戶體驗,同時還要注意
 android自定義ProgressView長條漸變色的進度條
android自定義ProgressView長條漸變色的進度條
最近在公司,項目不是很忙了,偶爾看見一個兄台在CSDN求助,幫忙要一個自定義的漸變色進度條,我當時看了一下進度條,感覺挺漂亮的,就嘗試的去自定義view實現了一個,廢話不
 Android開發-RecyclerView-AndroidStudio(七)屬性動畫(4)ChangeDuration
Android開發-RecyclerView-AndroidStudio(七)屬性動畫(4)ChangeDuration
RecyclerView改變數據:跟RemoveDuration、MoveDuration、AddDuration一樣,ChangeDuration默認的動畫屬性都是通過
 Android彈幕框架 黑暗火焰使
Android彈幕框架 黑暗火焰使
今天我將分享由BiliBili開源的Android彈幕框架(DanmakuFlameMaster)的學習經驗。我是將整個框架以model的形式引入項目中的,這樣更方便的觀