編輯:關於Android編程
一、執行命令
首先是啟動memcached 自帶參數如下:
-p設置TCP端口號(默認設置為: 11211) -U UDP監聽端口(默認: 11211, 0 時關閉) -l 綁定地址(默認:所有都允許,無論內外網或者本機更換IP,有安全隱患,若設置為127.0.0.1就只能本機訪問) -c max simultaneous connections (default: 1024) -d 以daemon方式運行 -u 綁定使用指定用於運行進程 -m 允許最大內存用量,單位M (默認: 64 MB) -P 將PID寫入文件 ,這樣可以使得後邊進行快速進程終止, 需要與-d 一起使用
客戶端通過網絡方式連接:
telnet 192.168.10.156 12121
然後就可以操作命令、常見命令如下:
set add replace get delete
command參數說明如下: command set/add/replace key key 用於查找緩存值 flags 可以包括鍵值對的整型參數,客戶機使用它存儲關於鍵值對的額外信息 expiration time 在緩存中保存鍵值對的時間長度(以秒為單位,0 表示永遠) bytes 在緩存中存儲的字節點 value 存儲的值(始終位於第二行)
二、命令執行流程代碼分析
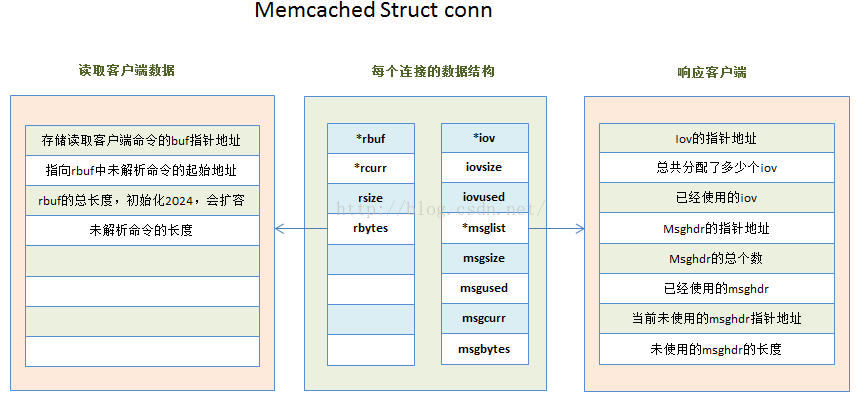
首先看一下工作線程中的命令數據結構:
/**
* The structure representing a connection into memcached.
*/
typedef struct conn conn;
非常重要的幾個參數:
char * rbuf:用於存儲客戶端數據報文中的命令。
int rsize:rbuf的大小。
char * rcurr:未解析的命令的字符指針。
int rbytes:為解析的命令的長度。
結構如下:
struct conn {
int sfd;
char *rbuf; /** buffer to read commands into */
char *rcurr; /** but if we parsed some already, this is where we stopped */
int rsize; /** total allocated size of rbuf */
int rbytes; /** how much data, starting from rcur, do we have unparsed */
/* data for the mwrite state */
struct iovec *iov;
int iovsize; /* number of elements allocated in iov[] */
int iovused; /* number of elements used in iov[] */
struct msghdr *msglist;
int msgsize; /* number of elements allocated in msglist[] */
int msgused; /* number of elements used in msglist[] */
int msgcurr; /* element in msglist[] being transmitted now */
int msgbytes; /* number of bytes in current msg */
LIBEVENT_THREAD *thread; /* Pointer to the thread object serving this connection */
...
};
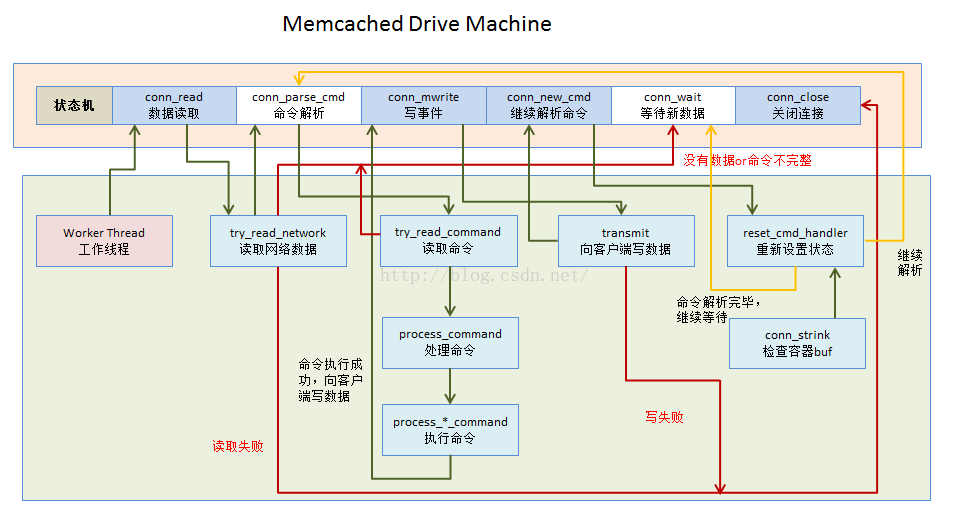
以上圖相當有水平,引用作者 http://calixwu.com/ 上的、自已就不再畫了。
以文字說明一下整體狀態機流程:
1. 當客戶端和Memcached建立TCP連接後,Memcached會基於Libevent的event事件來監聽客戶端新的連接及是否有可讀的數據。
2. 當客戶端有命令數據報文上報的時候,就會觸發drive_machine方法中的conn_read這個case狀態。
3. memcached通過try_read_network方法讀取客戶端的報文。如果讀取失敗,則返回conn_closing,去關閉客戶端的連接;如果沒有讀取到任何數據,則會返回conn_waiting,繼續等待客戶端的事件到來,並且退出drive_machine的循環;如果數據讀取成功,則會將狀態轉交給conn_parse_cmd處理,讀取到的數據會存儲在c->rbuf容器中。
4. conn_parse_cmd主要的工作就是用來解析命令。主要通過try_read_command這個方法來讀取c->rbuf中的命令數據,通過\n來分隔數據報文的命令。如果c->buf內存塊中的數據匹配不到\n,則返回繼續等待客戶端的命令數據報文到來conn_waiting;否則就會轉交給process_command方法,來處理具體的命令(命令解析會通過\0符號來分隔)。
5. process_command主要用來處理具體的命令。其中tokenize_command這個方法非常重要,將命令拆解成多個元素(KEY的最大長度250)。例如我們以get命令為例,最終會跳轉到process_get_command這個命令process_*_command這一系列就是處理具體的命令邏輯的。
6. 我們進入process_get_command,當獲取數據處理完畢之後,會轉交到conn_mwrite這個狀態。如果獲取數據失敗,則關閉連接。
7. 進入conn_mwrite後,主要是通過transmit方法來向客戶端提交數據。如果寫數據失敗,則關閉連接或退出drive_machine循環;如果寫入成功,則又轉交到conn_new_cmd這個狀態。
8. conn_new_cmd這個狀態主要是處理c->rbuf中剩余的命令。主要看一下reset_cmd_handler這個方法,這個方法回去判斷c->rbytes中是否還有剩余的報文沒處理,如果未處理,則轉交到conn_parse_cmd(第四步)繼續解析剩余命令;如果已經處理了,則轉交到conn_waiting,等待新的事件到來。在轉交之前,每次都會執行一次conn_shrink方法。
9. conn_shrink方法主要用來處理命令報文容器c->rbuf和輸出內容的容器是否數據滿了?是否需要擴大buffer的大小,是否需要移動內存塊。接受命令報文的初始化內存塊大小2048,最大8192。
三、下面以代碼簡要分析一下
1、讀寫事件回調函數:event_handler,這個方法中最終調用的是drive_machine
void event_handler(const int fd, const short which, void *arg) {
conn* c = (conn *) arg;
drive_machine(c);
}
static void drive_machine(conn *c) {
bool stop = false;
while(!stop) {
switch (c->state) {
case conn_waiting:
// 通過update_event函數確認是否為讀狀態,如果是則切到conn_read
if (!update_event(c, EV_READ | EV_PERSIST)) {
conn_set_state(c, conn_closing);
}
conn_set_state(c, conn_read);
stop = true;
break;
case conn_read:
// 讀取數據並根據read的情況切到不同狀態、正常情況切到conn_parse_cmd
res = try_read_network(c);
switch (res) {
case READ_NO_DATA_RECEIVED:
conn_set_state(c, conn_waiting);
break;
case READ_DATA_RECEIVED:
conn_set_state(c, conn_parse_cmd);
break;
case READ_ERROR:
conn_set_state(c, conn_closing);
break;
case READ_MEMORY_ERROR: /* Failed to allocate more memory */
/* State already set by try_read_network */
break;
}
break;
case conn_parse_cmd:
// 讀取命令並解析命令,如果數據不夠則切到conn_waiting
if (try_read_command(c) == 0) {
/* we need more data! */
conn_set_state(c, conn_waiting);
}
break;
case conn_mwrite:
res = transmit(c);
switch(res){
case TRANSMIT_COMPLETE:
if (c->state == conn_mwrite) {
/* XXX: I don't know why this wasn't the general case */
if(c->protocol == binary_prot) {
conn_set_state(c, c->write_and_go);
} else {
// 命令回復完成後、又切換到conn_new_cmd處理剩余的命令參數
conn_set_state(c, conn_new_cmd);
}
}
}
break;
...
}
}
}
static int try_read_command(conn *c) {
if (c->protocol == binary_prot) { // 二進制模式
dispatch_bin_command(c);
}else{
//查找命令中是否有\n,memcache的命令通過\n來分割
el = memchr(c->rcurr, '\n', c->rbytes);
//如果找到了\n,說明c->rcurr中有完整的命令了
cont = el + 1; //下一個命令開始的指針節點
//這邊判斷是否是\r\n,如果是\r\n,則el往前移一位
if ((el - c->rcurr) > 1 && *(el - 1) == '\r') {
el--;
}
//然後將命令的最後一個字符用 \0(字符串結束符號)來分隔
*el = '\0';
//處理命令,c->rcurr就是命令
process_command(c, c->rcurr);
//移動到下一個命令的指針節點
c->rbytes -= (cont - c->rcurr);
c->rcurr = cont;
}
}
// 處理具體的命令。將命令分解後,分發到不同的具體操作中去
static void process_command(conn *c, char *command) {
token_t tokens[MAX_TOKENS];
// 拆分命令:將拆分出來的命令元素放進tokens的數組中
ntokens = tokenize_command(command, tokens, MAX_TOKENS);
// 分解出來的命令的第一個參數為操作方法
1、process_get_command(c, tokens, ntokens, false); // "get"/"bget"
2、process_update_command(c, tokens, ntokens, comm, false); // "add"/"set"/...
3、process_get_command(c, tokens, ntokens, true); // "gets"
...>> 4-n
}
static inline void process_get_command(conn *c, token_t *tokens...){
it = item_get(key, nkey, c); // 內存存儲快塊取數據
if (it) { // 獲取到了數據
/*
* Construct the response. Each hit adds three elements to the
* outgoing data list:
* "VALUE "
* key
* " " + flags + " " + data length + "\r\n" + data (with \r\n)
*/
// 構建初始化返回出去的數據結構
add_iov(c, "VALUE ", 6);
add_iov(c, ITEM_key(it), it->nkey);
add_iov(c, ITEM_suffix(it), it->nsuffix - 2);
add_iov(c, suffix, suffix_len);
add_iov(c, "END\r\n", 5);
// 最後切到 conn_mwrite 即調用 transmit 函數
conn_set_state(c, conn_mwrite);
}
}
/*
* Returns an item if it hasn't been marked as expired,
* lazy-expiring as needed.
*/
item *item_get(const char *key, const size_t nkey, conn *c) {
item *it;
uint32_t hv;
hv = hash(key, nkey);
item_lock(hv);
it = do_item_get(key, nkey, hv, c);
item_unlock(hv);
return it;
}
// 向客戶端寫數據。寫完數據後,如果寫失敗,則關閉連接;如果寫成功,則會將狀態修改成conn_new_cmd,
// 繼續解析c->rbuf中剩余的命令
static enum transmit_result transmit(conn *c) {
//msghdr 發送數據的結構
struct msghdr *m = &c->msglist[c->msgcurr];
//sendmsg 發送數據方法
res = sendmsg(c->sfd, m, 0);
...
}
//重新設置命令handler
static void reset_cmd_handler(conn *c) {
c->cmd = -1;
c->substate = bin_no_state;
if (c->item != NULL) {
item_remove(c->item);
c->item = NULL;
}
conn_shrink(c); //這個方法是檢查c->rbuf容器的大小
//如果剩余未解析的命令 > 0的話,繼續跳轉到conn_parse_cmd解析命令
if (c->rbytes > 0) {
conn_set_state(c, conn_parse_cmd);
} else {
//如果命令都解析完成了,則繼續等待新的數據到來
conn_set_state(c, conn_waiting);
}
}
/*
* Shrinks a connection's buffers if they're too big. This prevents
* periodic large "get" requests from permanently chewing lots of server
* memory.
*
* This should only be called in between requests since it can wipe output
* buffers!
*/
static void conn_shrink(conn *c) { // 檢查rbuf的大小
if (c->rsize > READ_BUFFER_HIGHWAT && c->rbytes < DATA_BUFFER_SIZE) {
char *newbuf;
if (c->rcurr != c->rbuf)
memmove(c->rbuf, c->rcurr, (size_t)c->rbytes);
newbuf = (char *)realloc((void *)c->rbuf, DATA_BUFFER_SIZE);
if (newbuf) {
c->rbuf = newbuf;
c->rsize = DATA_BUFFER_SIZE;
}
c->rcurr = c->rbuf;
}
...
}
 Android插件開發——基礎篇
Android插件開發——基礎篇
Android插件開發初探 對於Android的插件化其實已經討論已久了,但是市面上還沒有非常靠譜成熟的插件框架供我們使用。這裡我們就嘗試性的對比一下Java中,我們使用
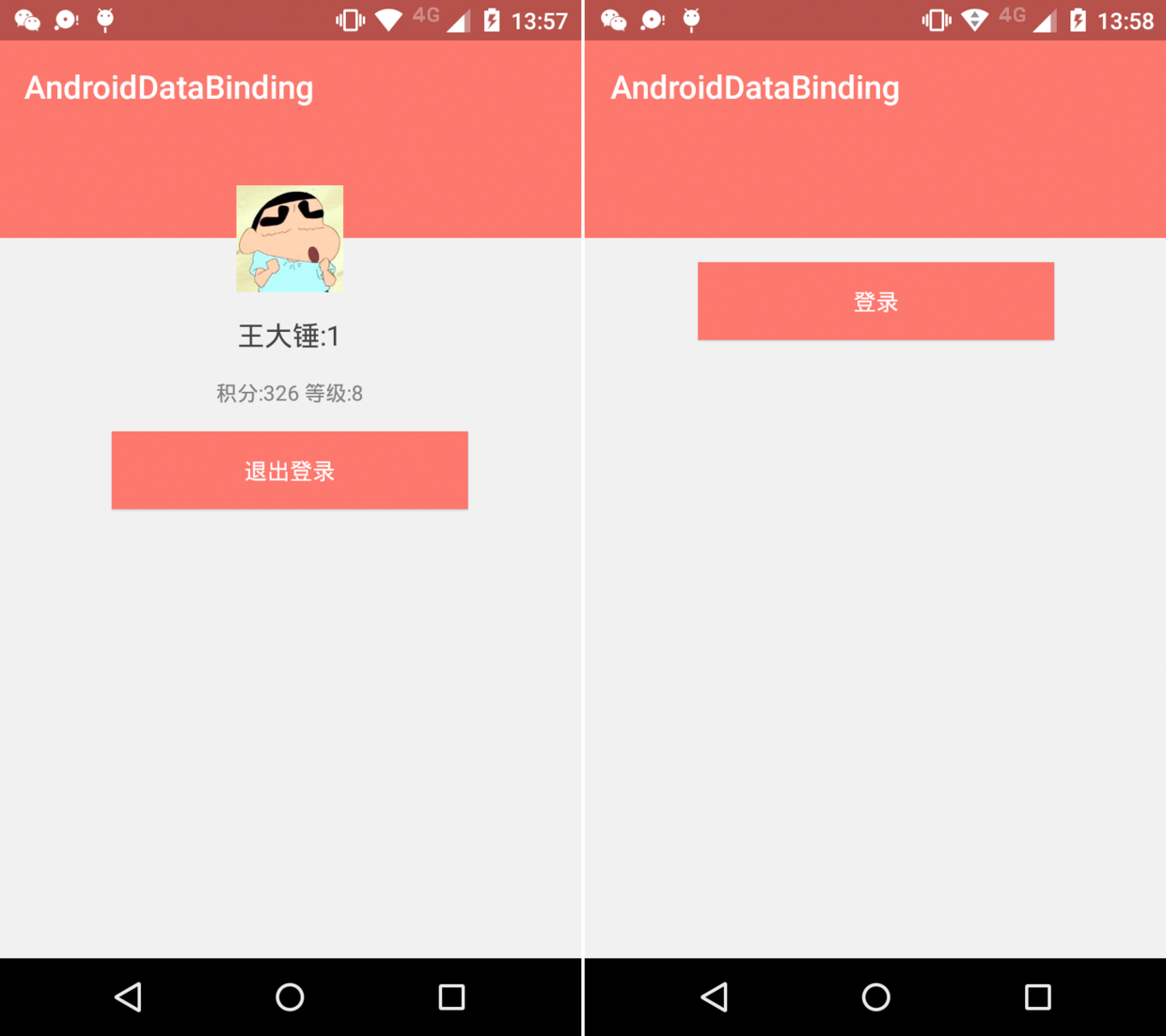 Android Data Binding
Android Data Binding
1 引入如何高效地實現以下界面?public class User { private String name; private int score;
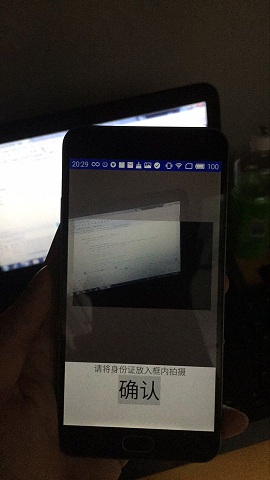 Android開發仿掃一掃實現拍攝框內的照片功能
Android開發仿掃一掃實現拍攝框內的照片功能
就是仿照現在掃一掃的形式,周圍是半透明的遮擋,然後中間是全透明的,拍攝後只截取框內的內容查了很多博客,實現起來真的太復雜了,本人比較怕麻煩所以在很多地方偷懶了先上效果圖:
 android 自定義控件之ViewGroup生命周期執行步驟
android 自定義控件之ViewGroup生命周期執行步驟
前言android 自定義控件之ViewGroup生命周期執行步驟。了解ViewGroup的生命周期的執行步驟對於自己自定義ViewGroup的時候十分重要,清楚了整個流