編輯:關於android開發
好久沒有寫博客了,瞬間感覺好多學了的東西不進行一個自我的總結與消化總歸變不成自己的。通過博客可能還可以找到一些當初在學習的時候沒有想到的問題。想了半天,從大二上學期自學Android以來還沒有對Android從啟動到程序運行期間進行一個完整的歸納,剛好最近又學到了一些新東西,那就以這篇博客為媒介,總結一下從Android啟動到程序運行期間發生的所有事吧。包括什麼ClassLoader, JVM,IPC, 消息處理機制要是總結到了就順帶BB一下。但是這裡就不包含很多細節了,比如為什麼PMS內部為什麼要這麼構造,好處是什麼,如果我來設計的話我會怎麼設計啊這種暫時就不總結了,因為我覺得以我現在的水平還有學習精力來說把這些細節都一個個的弄清楚有點沒抓住重點。現階段還是先能夠了解整個流程,有個大局觀才是最重要的。至於以後如果有需要或者是有精力的時候再一個個的突破。
發現本文的錯誤或者遺漏後會立刻更改
在正式開始之前還是忍不住想要BB一下最近參加的京東筆試,被坑得有點憋屈。憋屈啥勒,被編譯器坑了。這次京東的筆試說實話感覺真的好簡單,真的沒有什麼技術上的難點,但是尼瑪編程題把我坑了。提前一個小時把代碼在本地編譯器上編譯完成並通過,當時心裡還有些小激動,一提交,在線編譯器說得不到指定結果,尼瑪,頓時整個人都斯巴達了。最開始的時候還以為是自己本身代碼的Bug,後來順著思路又理了幾遍,完全沒問題啊,又自己創了幾個新的輸入也都能夠運行,返回正常結果。整個人都是崩潰的,在這上面花了20多分鐘時候不經意間瞥了一下左邊的樣例輸入和輸出,哦豁,這下全懂了。
因為我沒有很多這種參加在線筆試的經驗,也沒在網上怎麼刷題,所以在樣例輸入和輸出那裡摻雜了一些自己想當然的想法。
題目要求的樣例輸入是一直輸入,有兩種情況,一種情況返回No,一種情況返回Yes並返回對應的結果。是要求連續輸入的,也就是你在輸入的時候我至少要用一個數組或者是List、Map來保存你的輸入。當檢測到輸入為空也就是直接按了回車的同時就開始運行,然後再一次性的打印出結果。我不知道啊,第一次看這種樣例輸入輸出,一看以為只要能返回就好了,然後就是分開做的,輸入錯的就返回No,輸入對的就返回Yes和結果,並不能夠一起輸入及返回。而這個時候時間又過了好多了,改代碼的話整個代碼的架構都要變,時間上完全來不及。這筆試要是編程題錯了那估計是沒戲了。
這其實也怪自己吧,怨不得別的,只好等下次了,只是這次的題真的簡單,錯過了好可惜,畢竟還是非常想進京東鍛煉鍛煉的,就算進不了去體驗京東的面試,知道哪裡有不足也是好的。
上面BB了這麼多,也是超過了我的預料,這裡就正式開始這篇博客了。
首先,我們知道,Android是基於Linux的一個操作系統,它可以分為五層,下面是它的層次架構圖,可以記一下,因為後面應該會總結到SystemServer這些Application Framework層的東西

Android的五層架構從上到下依次是應用層,應用框架層,庫層,運行時層以及Linux內核層。
而在Linux中,它的啟動可以歸為一下幾個流程:
Boot Loader-》初始化內核-》。。。。。。
當初始化內核之後,就會啟動一個相當重要的祖先進程,也就是init進程,在Linux中所有的進程都是由init進程直接或間接fork出來的。
而對於Android來說,前面的流程都是一樣的,而當init進程創建之後,會fork出一個Zygote進程,這個進程是所有Java進程的父進程。我們知道,Linux是基於C的,而Android是基於Java的(當然底層也是C)。所以這裡就會fork出一個Zygote Java進程用來fork出其他的進程。【斷點1】
總結到了這裡就提一下之後會談到的幾個非常重要的對象以及一個很重要的概念。
ActivityManagerServices(AMS):它是一個服務端對象,負責所有的Activity的生命周期,ActivityThread會通過Binder與之交互,而AMS與Zygote之間進行交互則是通過Socket通信(IPC通信在之後會總結到) ActivityThread:它也就是我們俗稱的UI線程/主線程,它裡面存在一個main()方法,這也是APP的真正入口,當APP啟動時,就會啟動ActivityThread中的main方法,它會初始化一些對象,然後開啟消息循環隊列(之後總結),之後就會Looper.loop死循環,如果有消息就執行,沒有就等著,也就是事件驅動模型(edt)的原理。 ApplicationThread:它實現了IBinder接口,是Activity整個框架中客戶端和服務端AMS之間通信的接口,同時也是ActivityThread的內部類。這樣就有效的把ActivityThread和AMS綁定在一起了。 Instrumentation:這個東西我把它理解為ActivityThread的一個工具類,也算是一個勞動者吧,對於生命周期的所有操作例如onCreate最終都是直接由它來執行的。Android系統中的客戶端和服務器的概念
在Android系統中其實也存在著服務器和客戶端的概念,服務器端指的就是所有App共用的系統服務,比如上面的AMS,PackageManagerService等等,這些系統服務是被所有的App共用的,當某個App想要實現某個操作的時候,就會通知這些系統服務。
當Zygote被初始化的時候,會fork出System Server進程,這個進程在整個的Android進程中是非常重要的一個,地位和Zygote等同,它是屬於Application Framework層的,Android中的所有服務,例如AMS, WindowsManager, PackageManagerService等等都是由這個SystemServer fork出來的。所以它的地位可見一斑。
而當System Server進程開啟的時候,就會初始化AMS,同時,會加載本地系統的服務庫,創建系統上下文,創建ActivityThread及開啟各種服務等等。而在這之後,就會開啟系統的Launcher程序,完成系統界面的加載與顯示。【斷點2】
Context是一個抽象類,下面是它的注釋信息,摘自源碼。
/**
* Interface to global information about an application environment. This is
* an abstract class whose implementation is provided by
* the Android system. It
* allows access to application-specific resources and classes, as well as
* up-calls for application-level operations such as launching activities,
* broadcasting and receiving intents, etc.
*/
public abstract class Context {
從上面的這段話可以簡單理解一下,Context是一個關於應用程序環境的全局變量接口,通過它可以允許去獲得資源或者類,例如啟動Activity,廣播,intent等等。
我的理解:Context的具體實現是Application, Activity,Service,通過Context能夠有權限去做一些事情,其實我覺得就是一個運行環境的問題。
需要注意的地方
Android開發中由於很多地方都包含了Context的使用,因此就必須要注意到內存洩露或者是一些可能會引起的問題。
例如在Toast中,它的Context就最好設置為Application Context,因為如果Toast在顯示東西的時候Activity關閉了,但是由於Toast仍然持有Activity的引用,那麼這個Activity就不會被回收掉,也就造成了內存洩露。
上面舉例的時候舉到了Toast,其實Toast也是很有意思的一個東西,它的show方法其實並不是顯示一個東西這麼簡單。
Toast實際上是一個隊列,會通過show方法把新的任務加入到隊列當中去,列隊中只要存在消息就會彈出來使用,而隊列的長度據說默認是40個(這是網上搜出來的,我在源碼中沒找到對應的設置,感覺也沒啥必要就沒找了)。
所以這裡就要注意一下show這個操作了,它並不是顯示內容,而是把內容入隊列。
/**
* Show the view for the specified duration.
*/
public void show() {
if (mNextView == null) {
throw new RuntimeException("setView must have been called");
}
INotificationManager service = getService();
String pkg = mContext.getOpPackageName();
TN tn = mTN;
tn.mNextView = mNextView;
try {
service.enqueueToast(pkg, tn, mDuration);
} catch (RemoteException e) {
// Empty
}
}
對於Handler來說,如果我們直接在AndroidStudio中創建一個非靜態內部類Handler,那麼Handler這一大片的區域會被AS標記為黃色,這個應該很多人都遇到過吧。實際上是因為這樣設置會造成內存洩露,因為每一個非靜態內部類都會持有一個外部類的引用,那麼這裡也就產生了一個內存洩露的可能點,如果當Activity被銷毀時沒有與Handler解除,那麼Handler仍然會持有對該Activity的引用,那麼就造成了內存洩露。
解決方案
使用static修飾Handler,這樣也就成了一個靜態內部類,那麼就不會持有對外部類的引用了。而這個時候就可以在Handler中創建一個WeakReference(弱引用)來持有外部的對象。只要外部解除了與該引用的綁定,那麼垃圾回收器就會在發現該弱引用的時候立刻回收掉它。
上面扯到了弱引用,就再BB一下四種引用方式吧。
強引用:垃圾回收器打死都不會回收掉一個強引用的,那怕是出現OOM也不會回收掉強引用,所有new出來的都是強引用。軟引用:垃圾回收器會在內存不足的情況下回收掉軟引用,如果內存充足的話不會理它弱引用:它跟軟引用類似,但是它更脆弱,只要垃圾回收器一發現它,就會立刻回收掉它。比如一個對象持有一個強引用和弱引用,當強引用被取消時,那麼只要GC發現了它,就會立刻回收掉。只是GC發現它的這個過程是不確定的,有可能不會馬上發生,所以它可能還會多活一會,中間存在一個優先級。虛引用:它跟上面3種方式都不同。我對虛引用的理解就是如果一個對象持有虛引用,那麼就可以在被GC回收前進行一些設定好的工作等等。因為虛引用有個機制,因為虛引用必須和引用隊列聯合使用,當垃圾回收器准備回收一個對象時,如果發現它還有虛引用,就回在回收對象的內存前,把這個虛引用加入到與之關聯的引用隊列中。而程序如果判斷到引用隊列中已經加入了虛引用,那麼就可以了解到被引用的對象馬上就要被垃圾回收了,這個時候就可以做些被回收之前的事情啦。類加載器按層次從頂層到下依次為Boorsrtap ClassLoader(啟動類加載器),Extension ClassLoader(拓展類加載器),ApplicationClassLoader(應用程序類加載器)
判斷兩個類是否是同一個類就是看它們是否是由同一個類加載器加載而來。
這裡就需要介紹一下雙親委派模式了:
雙親委派模式的意思就是:除了啟動類加載器之外,其余的加載器都需要指定一個父類的加載器,當需要加載的時候會先讓父類去試著加載,如果父類無法加載也就是找不到這個類的話就會讓子類去加載
好處:防止內存中出現多份同樣的字節碼
比如類A和類B都要加載system類,如果不是委托的話,類A就會加載一份,B也會加載一份,那麼就會出現兩份SYstem字節碼
如果使用委托機制,會遞歸的向父類查找,也就是首選用Bootstrap嘗試加載,如果找不到再向下,如果A用這個已經加載了的話會直接返回內存中的system而不需要重新加載。那麼就只會存在一份
對於Java來說,類是需要使用到時才會加載,這裡也就出現了一個延遲加載的效果。而在延遲加載的時候,會默認保持同步。這也就產生了一種單例模式的方式,具體的看我之前的博客:設計模式_單例模式
我覺得在android所有的創建單例模式方法中裡延遲加載方式是最好吧,雖然枚舉比延遲加載更好,effiective java中也很推薦,但是並不怎麼適用於Android,Android裡枚舉的消耗是static的兩倍,延遲加載的話只要我們在使用延遲加載方式時做好反序列化的返回值readResolve()准備就好了。
上面BB了太多其他的,現在有點緩不過來,下次自己看自己博客的時候會不會都被自己的思路帶得亂七八糟的。
上面的時候我們就已經完成了整個Android系統的開機以及初始化。接下來就可以B一下從點擊APP圖標開始到APP內部程序運行起來的流程了。
當我們點擊屏幕時,觸摸屏的兩層電極會連接在一起,也就產生了一個電壓(具體的我忘了,書上有,圖找不到了),當產生電壓的時候,就可以通過對應的驅動把當前按壓點的XY坐標傳給上層,這裡也就是操作系統。操作系統在獲取到XY值的時候,就會對按壓點的范圍進行一個判斷,如果確定按壓點處於一個APP圖標或者是Button等等的范圍中時,操作系統也就會認為用戶當前已經點擊了這個東西,啟動對應的監聽。
而當系統判斷我們點擊的是APP圖標時,該App就由Launcher開始啟動了【斷點3】
Launcher是一個繼承自Activity,同時實現了點擊事件,長按事件等等的一個應用程序。
public final class Launcher extends Activity
implements View.OnClickListener,OnLongClickListener, LauncherModel.Callbacks,View.OnTouchListener
當我們點擊一個APP的圖標時,會調用Launcher內部的startActivitySafely()方法,而這個方法則會進行兩件事,一個是啟動目標activity,另一個功能就是捕獲異常ActivityNotFoundException,也就是常見的“找不到activity,是否已經在androidmenifest文件中注冊?”。而在startActivity方法中,經過一系列的轉換最終會調用到startActivityForResult這個方法。
@Override
public void startActivity(Intent intent, @Nullable Bundle options) {
if (options != null) {
startActivityForResult(intent, -1, options);
} else {
// Note we want to go through this call for compatibility with
// applications that may have overridden the method.
startActivityForResult(intent, -1);
}
}
所以實際上,我對整個Android的界面是這樣理解的:
當系統完成初始化以及各種服務的創建之後,就會啟動Launcher這個應用程序(它也是繼承自Activity的,包含自己對應的xml布局文件),然後再把各種圖標按照一個正常APP布局的方式放在上面,當我們點擊APP圖標時,也就相當於在Launcher這個APP應用程序中通過startActivity(在底層最後會轉為startActivityForResult)來啟動這個APP。簡單的講,我覺得就是一個主要的APP(Launcher)裡面啟動了其他的功能APP,例如QQ、微信這些。【個人理解,如果以後發現不對再修改】
當我們手指按下時,Android是如何處理點擊事件的呢?如何確定是讓哪一個控件來處理呢?
簡單一句話:層層傳遞-冒泡的方式處理
舉個例子:現在公司來了個小項目,老板一看分配給經理做,經理一看分配給小組長,小組長一看好簡單,分配給組員。如果在這個傳遞過程中(也就是還為分配到最底部時),某一層覺得我來負責這個比較好的話就會攔截掉這個消息,然後把它處理了,下面的就收不到有消息的這個通知。如果一直到了底層的話,組員如果能完成,就完成它。如果不能完成,那麼就報告給組長,說組長我做不來,邊學邊做要影響進度。組長一看我也做不來,就給經理,經理一看我也不會,就給老板。這樣也就一層層的傳遞了。
總結一下就是消息從上到下依次傳遞,如果在傳遞的過程中被攔截了就停止下傳。如果沒有被攔截,就一直傳遞到底部,如果底部不能夠消耗該消息,那麼就又一層層的返回來,返給上層,直到被消耗或者是到達最頂層。
在Android中,存在三個重要的方法:
dispathTouchEvent(MotionEvent ev) onInterceptTouchEvent(MotionEvent ev) onTouchEvent(MotionEvent ev)第一個方法負責事件的分發,它的返回值就是表示是否消耗當前事件。
第二個方法是用於判斷是否攔截該消息,如果當前View攔截了某個時間,那麼在同一個事件序列中,此方法不會被再次調用。返回結果表示是否攔截當前事件
第三個方法就是處理事件。返回結果表示是否消耗當前事件,如果不小號,則在同一時間序列中,當前View無法再次接收到事件。
對於一個根ViewGroup來說,點擊事件產生後,首先會傳遞給它,調用它的dispath方法。如果這個ViewGroup的onIntercept方法返回true就表示它要攔截當前事件,false就表示不攔截,這個時候事件就會繼續傳遞給子元素,接著調用子元素的dispath方法,直到被處理。
順帶總結一下滑動沖突的解決吧
View的滑動沖突一般可以分為三種:
比如說一個常見的,外部一個ListView,裡面一個ScrollView。這個時候該怎麼解決呢?其實這裡想到了ViewPager,它裡面實際上是解決了滑動沖突的,可以借鑒一下它的。
滑動處理規則
一般來說,我們可以根據用戶手指滑動的方向以及角度來判斷用戶是要朝著哪個方向去滑動。而很多時候還可以根據項目的需求來指定一套合適的滑動方案。
外部攔截法
這種方法就是指所有的點擊時間都經過父容器的攔截處理,如果父容器需要此時間就攔截,如果不需要此事件就不攔截。通過重寫父容器的onInterceptTouchEvent方法:
case MotionEvent.ACTION_DOWN:
intercepted = false;
break;
case MotionEvent.ACTION_MOVE:
if(父類容器需要) {
intercepted = true;
} else {
intercepted = false;
}
break;
case MotionEvent.ACTION_UP:
intercepted = false;
break;
return intercepted;
這裡有一點需要注意,ACTION_DOWN事件父類容器就必須返回false,因為如果父類容器攔截了的話,後面的Move等所有事件都會直接由父類容器處理,就無法傳給子元素了。UP事件也要返回false,因為它本身來說沒有太多的意義,但是對於子元素就不同了,如果攔截了,那麼子元素的onClick事件就無法觸發。
內部攔截法
這種方法指的是父容器不攔截任何時間,所有的事件都傳遞給子元素,如果子元素需要此事件就直接消耗掉,否則就交給父容器進行處理。它需要配合requestDisallowInterceptTouchEvent方法才能正常工作。我們需要重寫子元素的dispatch方法
case MotionEvent.ACTION_DOWN:
parent.requestDisallowInterceptTouchEvent(true);
break;
MotionEvent.ACTION_MOVE:
if(父容器需要此類點擊事件) {
parent.requestDisallowInterceptTouchEvent(false);
}
break;
return super.dispatchTouchEvent(event);
這種方法的話父類容器需要默認攔截除了ACTION_DOWN以外的其他時間,這樣當子元素調用request方法的時候父元素才能繼續攔截所需的事件。
其他的
如果覺得上面兩個方式太復雜,看暈了,其實也可以自己根據項目的實際需要來指定自己的策略實現。例如根據你手指按的點的位置來判斷你當前觸碰的是哪個控件,以此來猜測用戶是否是要對這個控件進行操作。如果點擊的是空白的地方,就操作外部控件即可。
【等有時間了就把ViewPager的處理總結一下,挺重要的】
Android的消息機制主要是指Handler的運行機制,Handler的運行需要底層的MessageQueue和Looper的支撐
雖然MessageQueue叫做消息隊列,但是實際上它內部的存儲結構是單鏈表的方式。由於Message只是一個消息的存儲單元,它不能去處理消息,這個時候Looper就彌補了這個功能,Looper會以無限循環的形式去查找是否有新消息,如果有的話就處理消息,否則就一直等待(機制等會介紹)。而對於Looper來說,存在著另外的一個很重要的概念,就是ThreadLocal。
ThreadLocal它並不是一個線程,而是一個可以在每個線程中存儲數據的數據存儲類,通過它可以在指定的線程中存儲數據,數據存儲之後,只有在指定線程中可以獲取到存儲的數據,對於其他線程來說則無法獲取到該線程的數據。
舉個例子,多個線程通過同一個ThreadLocal獲取到的東西是不一樣的,就算有的時候出現的結果是一樣的(偶然性,兩個線程裡分別存了兩份相同的東西),但他們獲取的本質是不同的。
那為什麼有這種區別呢?為什麼要這樣設計呢?
先來研究一下為什麼會出現這個結果。
在ThreadLocal中存在著兩個很重要的方法,get和set方法,一個讀取一個設置。
/**
* Returns the value of this variable for the current thread. If an entry
* doesn't yet exist for this variable on this thread, this method will
* create an entry, populating the value with the result of
* {@link #initialValue()}.
*
* @return the current value of the variable for the calling thread.
*/
@SuppressWarnings("unchecked")
public T get() {
// Optimized for the fast path.
Thread currentThread = Thread.currentThread();
Values values = values(currentThread);
if (values != null) {
Object[] table = values.table;
int index = hash & values.mask;
if (this.reference == table[index]) {
return (T) table[index + 1];
}
} else {
values = initializeValues(currentThread);
}
return (T) values.getAfterMiss(this);
}
/**
* Sets the value of this variable for the current thread. If set to
* {@code null}, the value will be set to null and the underlying entry will
* still be present.
*
* @param value the new value of the variable for the caller thread.
*/
public void set(T value) {
Thread currentThread = Thread.currentThread();
Values values = values(currentThread);
if (values == null) {
values = initializeValues(currentThread);
}
values.put(this, value);
}
摘自源碼
首先研究它的get方法吧,從注釋上可以看出,get方法會返回一個當前線程的變量值,如果數組不存在就會創建一個新的。
這裡有幾個很重要的詞,就是“當前線程”和“數組”。
這裡提到的數組對於每個線程來說都是不同的,values.table,而values是通過當前線程獲取到的一個Values對象,因此這個數組是每個線程唯一的,不能共用,而下面的幾句話也更直接了,獲取一個索引,再返回通過這個索引找到數組中對應的值。這也就解釋了為什麼多個線程通過同一個ThreadLocal返回的是不同的東西。
那這裡為什麼要這麼設置呢?翻了一下書,搜了一下資料:
ThreadLocal在日常開發中使用到的地方較少,但是在某些特殊的場景下,通過ThreadLocal可以輕松實現一些看起來很復雜的功能。一般來說,當某些數據是以線程為作用域並且不同線程具有不同的數據副本的時候,就可以考慮使用ThreadLocal。例如在Handler和Looper中。對於Handler來說,它需要獲取當前線程的Looper,很顯然Looper的作用域就是線程並且不同的線程具有不同的Looper,這個時候通過ThreadLocal就可以輕松的實現Looper在線程中的存取。如果不采用ThreadLocal,那麼系統就必須提供一個全局的哈希表供Handler查找指定的Looper,這樣就比較麻煩了,還需要一個管理類。 ThreadLocal的另一個使用場景是復雜邏輯下的對象傳遞,比如監聽器的傳遞,有些時候一個線程中的任務過於復雜,就可能表現為函數調用棧比較深以及代碼入口的多樣性,這種情況下,我們又需要監聽器能夠貫穿整個線程的執行過程。這個時候就可以使用到ThreadLocal,通過ThreadLocal可以讓監聽器作為線程內的全局對象存在,在線程內通過get方法就可以獲取到監聽器。如果不采用的話,可以使用參數傳遞,但是這種方式在設計上不是特別好,當調用棧很深的時候,通過參數來傳遞監聽器這個設計太糟糕。而另外一種方式就是使用static靜態變量的方式,但是這種方式存在一定的局限性,拓展性並不是特別的強。比如有10個線程在執行,就需要提供10個監聽器對象。上面提到了Handler/Looper/Message Queue,它們實際上是一個整體,只不過我們在開發中接觸更多的是Handler而已,Handler的主要作用是將一個任務切換到某個指定的線程中去執行,而Android之所以提供這個機制是因為Android規定UI只能在主線程中進程,如果在子線程中訪問UI就會拋出異常。
為什麼Android不允許在子線程訪問UI
其實這一點不僅僅是對於Android,對於其他的所有圖形界面現在都采用的是單線程模式。
因為對於一個多線程來說,如果子線程更改了UI,那麼它的相關操作就必須對其他子線程可見,也就是Java並發中很重要的一個概念,線程可見性,Happen-before原則【下篇博客總結一下自己對Java並發的理解吧,挺重要的,總結完後再把傳送門貼過來】而一般來說,對於這種並發訪問,一般都是采用加鎖的機制,但是加鎖的機制存在很明顯的問題:讓UI訪問間的邏輯變得復雜,同時效率也會降低。甚至有的時候還會造成死鎖的情況,這個時候就麻煩了。
而至於究竟能不能夠實現這種UI界面的多線程呢?SUN公司的某個大牛(忘了是誰,很久之前看的,好像是前副總裁)說:“行肯定是沒問題,但是非常考技術,因為必須要考慮到很多種情況,這個時候就需要技術專家來設計。而這種設計出來的東西對於廣大普通程序員來說又是異常頭疼的,就算是實現了多線程,普通人用起來也是怨聲載道的。所以建議還是單線程”。
順帶著BB一下死鎖。
死鎖的四個必要條件
互斥條件:資源不能被共享,只能被同一個進程使用請求與保持條件:已經得到資源的進程可以申請新的資源非剝奪條件:已經分配的資源不能從相應的進程中被強制剝奪循環等待條件:系統中若干進程組成環路,該環路中每個進程都在等待相鄰進程占用的資源舉個常見的死鎖例子:進程A中包含資源A,進程B中包含資源B,A的下一步需要資源B,B的下一步需要資源A,所以它們就互相等待對方占有的資源釋放,所以也就產生了一個循環等待死鎖。
處理死鎖的方法
忽略該問題,也就是鴕鳥算法。當發生了什麼問題時,不管他,直接跳過,無視它。檢測死鎖並恢復資源進行動態分配破除上面的四種死鎖條件之一MessageQueue主要包含兩個操作:插入和讀取,讀取操作本身會伴隨著刪除操作,插入和讀取對應的方法分別為enqueueMessage和next,其中enqueueMessage的作用是往消息隊列中插入一條消息,而next的作用是從消息隊列中取出一條消息並將其從消息隊列中移除。這也就是為什麼使用的是一個單鏈表的數據結構來維護消息列表,因為它在插入和刪除上比較有優勢(把下一個連接的點切換一下就完成了)。
而對於MessageQueue的插入操作來說,沒什麼可以看的,也就這樣吧,主要需要注意的是它的讀取方法next。
Message next() {
// Return here if the message loop has already quit and been disposed.
// This can happen if the application tries to restart a looper after quit
// which is not supported.
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
int pendingIdleHandlerCount = -1; // -1 only during first iteration
int nextPollTimeoutMillis = 0;
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
// Try to retrieve the next message. Return if found.
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
// Stalled by a barrier. Find the next asynchronous message in the queue.
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
} else {
// No more messages.
nextPollTimeoutMillis = -1;
}
// Process the quit message now that all pending messages have been handled.
if (mQuitting) {
dispose();
return null;
}
// If first time idle, then get the number of idlers to run.
// Idle handles only run if the queue is empty or if the first message
// in the queue (possibly a barrier) is due to be handled in the future.
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
mBlocked = true;
continue;
}
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// Run the idle handlers.
// We only ever reach this code block during the first iteration.
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
// Reset the idle handler count to 0 so we do not run them again.
pendingIdleHandlerCount = 0;
// While calling an idle handler, a new message could have been delivered
// so go back and look again for a pending message without waiting.
nextPollTimeoutMillis = 0;
}
}
源碼有點長,總結一下就是:
next方法它是一個死循環,如果消息隊列中沒有消息,那麼next方法就會一直阻塞在這裡,當有新的消息來的時候,next方法就會返回這條信息並將其從單鏈表中移除。
而這個時候勒Looper就等著的,它也是一直循環循環,不停地從MessageQueue中查看是否有新消息,如果有新消息就會立刻處理,否則就會一直阻塞在那裡。而對於Looper來說,它是只能創建一個的,這個要歸功與它的prepare方法。
/** Initialize the current thread as a looper.
* This gives you a chance to create handlers that then reference
* this looper, before actually starting the loop. Be sure to call
* {@link #loop()} after calling this method, and end it by calling
* {@link #quit()}.
*/
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
從這裡我們就可以看出該prepare方法會首先檢測是否已經存在looper了,如果不存在,就創建一個新的;如果存在,就拋出異常。
而之後使用Looper.loop()就可以開啟消息循環了。
/**
* Run the message queue in this thread. Be sure to call
* {@link #quit()} to end the loop.
*/
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
// Make sure the identity of this thread is that of the local process,
// and keep track of what that identity token actually is.
Binder.clearCallingIdentity();
final long ident = Binder.clearCallingIdentity();
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
// Make sure that during the course of dispatching the
// identity of the thread wasn't corrupted.
final long newIdent = Binder.clearCallingIdentity();
if (ident != newIdent) {
Log.wtf(TAG, "Thread identity changed from 0x"
+ Long.toHexString(ident) + " to 0x"
+ Long.toHexString(newIdent) + " while dispatching to "
+ msg.target.getClass().getName() + " "
+ msg.callback + " what=" + msg.what);
}
msg.recycleUnchecked();
}
}
從這裡面我們可以看到它也是個死循環,會不停的調用queue.next()方法來獲取信息,如果沒有,就return,如果有就處理。
注意
當然了,這裡有一個很重要的點,一般可能會忘,那就是在子線程中如果手動為其創建了Looper,那麼在所有的事情完成以後應該調用quit方法來終止消息循環,否則這個子線程就會一直處於等待狀態,而如果退出Looper之後,這個線程就會立刻終止,所以建議不需要使用的時候終止Looper。
Handler
上面總結了Looper和MessageQueue,這裡就對Handler進行一個總結吧。它的工作主要包含消息的發送和接受過程,消息的發送可以通過post的一系列方法以及send的一系列方法來實現,post的一系列方法最終是通過send的一系列方法來實現的。
實際上它發送消息的過程僅僅是向消息隊列中插入了一條消息,MessageQueue的next方法就會返回這條消息給Looper,Looper在收到消息之後就會開始處理了。最後由Looper交給Handler處理(handleMessage()方法)。
上面總結完了Android的消息處理機制,那麼就順帶總結一下IPC通信吧,畢竟上面提到過那麼多次Binder和Socket。
資料:為什麼Android要采用Binder作為IPC機制?
知乎上面的回答相當的好,這個博主對系統底層也是頗有鑽研,學習。
這裡就結合上面的知乎回答以及加上《Linux程序設計》還有一本Linux內核剖析(書名忘了但是講得真的非常好),摻雜一些個人的理解。
進程的定義
UNIX標准把進程定義為:“一個其中運行著一個或多個進程的地址控件和這些線程所需要的系統資源”。目前,可以簡單的把進程看做正在運行的程序。
進程都會被分配一個唯一的數字編號,我們成為PID(也就是進程標識符),它通常是一個取值范圍從2到32768的正整數。當進程被啟動時,系統將按順序選擇下一個未被使用的數字作為PID,當數字已經回繞一圈時,新的PID重新從2開始,數字1一般是為init保留的。在進程中,存在一個自己的棧空間,用於保存函數中的局部變量和控制函數的調用與返回。進程還有自己的環境空間,包含專門為這個進程建立的環境變量,同時還必須要維護自己的程序計數器,這個計數器用來記錄它執行到的位置,即在執行線程中的位置。
在Linux中可以通過system函數來啟動一個進程
守護進程
這裡就需要提到一個守護進程了,這個在所有的底層中經常都會被提到。
在linux或者unix操作系統中在系統引導的時候會開啟很多服務,這些服務就叫做守護進程。為了增加靈活性,root可以選擇系統開啟的模式,這些模式叫做運行級別,每一種運行級別以一定的方式配置系統。 守護進程是脫離於終端並且在後台運行的進程。守護進程脫離於終端是為了避免進程在執行過程中的信息在任何終端上顯示並且進程也不會被任何終端所產生的終端信息所打斷。
守護進程常常在系統引導裝入時啟動,在系統關閉時終止。如果想要某個進程不因為用戶或終端或其他的變化而受到影響,那麼就必須把這個進程變成一個守護進程
防止手機服務後台被殺死
是不是在手機的設置界面看當前正在運行的服務時會發現有的APP不止存在一個服務?有的APP後台存在兩個,有的存在三個?有的流氓軟件也會這麼設置,這樣的話就可以一直運行在後台,用戶你關也關不了(倒不是說所有這麼設置的都是流氓軟件,因為有的軟件需要保持一個長期的後台在線,這是由功能決定的)。
這裡有兩種方法(可能還有更多,這裡只總結我了解的):
第一種方法就是利用android中service的特性來設置,防止手機服務後台被殺死。通過更改onStartCommand方法的返回值,將service設置為粘性service,那麼當service被kill的時候就會將服務的狀態返回到最開始啟動的狀態,也就是運行的狀態,所以這個時候也就會再次重新運行。但是需要注意一點,這個時候的intent值就為空了,獲取的話需要注意一下這一點。第二種就是fork出一個C的進程,因為在Linux中,子類進程在父類被殺死銷毀的時候不會隨之殺死,它會被init進程領養。所以也就可以使用這一個方法,利用主進程fork出一個C進程在後台運行,一旦檢測到服務被殺死(檢測的方式多種,可使用觀察者模式,廣播,輪詢等等),就重啟服務即可IPC通信
上面總結了進程的相關基礎,這裡就開始總結一下進程間通信(IPC
)的問題了。
現在Linux現有的所有IPC方式:
到了這裡,就有了問題,為什麼在Linux已經存在這麼多優良的IPC方案時,Android還要采取一種新的Binder機制呢?
猜測:我覺得Android采用這種新的方式(當然也大面積的同時使用Linux的IPC通信方式),最多兩個原因:
資料
對於Binder來說,存在著以下的優勢:
性能角度:Binder的數據拷貝只需要一次,而管道、消息隊列、Socket都需要2次,而共享內存是一次都不需要拷貝,因此Binder的性能僅次於共享內存 穩定性來說:Binder是基於C/S架構的,也就是Client和Server組成的架構,Client端有什麼需求,直接發送給Server端去完成,架構清晰,分工明確。而共享內存的實現方式復雜,需要充分考慮訪問臨界資源的並發同步問題,否則可能會出現死鎖等問題。從穩定性來說,Binder的架構優於共享內存。 從安全的角度:Linux的傳統IPC方式的接收方無法獲得對方進程可靠的UID(用戶身份證明)/PID(進程身份證明),從而無法鑒別對方身份,而Android是一個對安全性能要求特別高的操作系統,在系統層面需要對每一個APP的權限進行管控或者監視,對於普通用戶來說,絕對不希望從App商店下載偷窺隱射數據、後台造成手機耗電等問題。傳統的Linux IPC無任何保護措施,完全由上層協議來確保。而在Android中,操作系統為每個安裝好的應用程序分配了自己的UID,通過這個UID可以鑒別進程身份。同時Android系統對外只暴露Client端,Client端將任務發送給Server端,Server端會根據權限控制策略判斷UID/PID是否滿足訪問權限。也就是說Binder機制對於通信雙方的身份是內核進行校驗支持的。例如Socket方式只需要指導地址就可以連接,他們的安全機制需要上層協議來假設 從語言角度:Linux是基於C的,而Android是基於Java的,而Binder是符合面向對象思想的。它的實體位於一個進程中,而它的引用遍布與系統的各個進程之中,它是一個跨進程引用的對象,模糊了進程邊界,淡化了進程通信的過程,整個系統仿佛運行於同一個面向對象的程序之中。 從公司角度:Linux內核是開源的,GPL協議保護,受它保護的Linux Kernel是運行在內核控件,對於上層的任何類庫、服務等只要進行系統調用,調用到底層Kernel,那麼也必須遵循GPL協議。而對於Android來說,Google巧妙地將GPL協議控制在內核控件,將用戶控件的協議采用Apache-2.0協議(允許基於Android的開發商不向社區反饋源碼)。剛才談到Binder的時候提了一下效率的問題,那這裡就不得不講到反射了。
反射它允許一個類在運行過程中獲得任意類的任意方法,這個是Java語言的一個很重要的特性。它方便了程序員的編寫,但是降低了效率。
實際上,對於只要不是特別大的項目(非Android),反射對於效率的影響微乎其微,而與之對比的開發成本來說就更劃算了。
但是,Android是一個用於手機的,它的硬件設施有限,我們必須要考慮到它的這個因素,用戶體驗是最重要的。以前看到過國外的一項統計。在一個APP中的Splash中使用了反射,結果運行時間增加了一秒,這個已經算是很嚴重的效率影響了。
為什麼反射影響效率呢
這裡就需要提到一個東西,JIT編譯器。JIT編譯器它可以把字節碼文件轉換為機器碼,這個是可以直接讓處理器使用的,經過它處理的字節碼效率提升非常大,但是它有一個缺點,就是把字節碼轉換成機器碼的過程很慢,有的時候甚至還超過了不轉換的代碼效率(轉換之後存在一個復用的問題,對於轉換了的機器碼,使用的次數越多就越值的)。因此,在JVM虛擬機中,也就產生了一個機制,把常用的、使用頻率高的字節碼通過JIT編譯器轉換,而頻率低的就不管它。而反射的話則是直接越過了JIT編譯器,不管是常用的還是非常用的字節碼一律沒有經過JIT編譯器的轉化,所以效率就會低。
而在Android裡面,5.0之前使用的是Davlik虛擬機,它就是上面的機制,而在Android5.0之後Google使用了一個全新的ART虛擬機全面代替Davlik虛擬機。
ART虛擬機會在程序安裝時直接把所有的字節碼全部轉化為機器碼,雖然這樣會導致安裝時間邊長,但是程序運行的效率提升非常大。
【疑問:那在Android5.0之後的系統上,反射會不會沒影響了?由於現在做項目的時候更多考慮的是向下兼容,單獨考慮5.0的情況還沒有,等以後有需求或者是有機會的時候再深入了解一下,以後更新】
剛才總結了Android的消息處理機制和IPC通信,那麼我們主線程的消息處理機制是什麼時候開始的呢?因為我們知道在主線程中我們是不需要手動調用Looper.prepare()和Looper.loop()的。
Android的主線程就是ActivityThread,主線程的入口方法是main方法,在main方法中系統會通過Looper.prepareMainLooper()來創建主線程的Looper以及MessageQueue,並通過Looper.loop來開啟消息循環,所以這一步實際上是系統已經為我們做了,我們就不再需要自己來做。
ActivityThread通過AppplicationThread和AMS進行進程件通信,AMS以進程間通信的方式完成ActivityThread的請求後會回調ApplicationThread中的Binder方法,然後ApplicationThread會向Handler發送消息,Handler收到消息後會將ApplicationThread中的邏輯切換到主線程中去執行,這個過程就是主線程的消息循環模型。
上面總結到了APP開始運行,依次調用onCreate/onStart/onResume等方法,那麼在onCreate方法中我們經常使用的setContentView和findViewById做了什麼事呢?
首先,就考慮到第一個問題,也就是setContentView這個東西做了什麼事,這裡就要對你當前繼承的Activity分類了,如果是繼承的Activity,那麼setContentView源碼是這樣的:
/**
* Set the activity content from a layout resource. The resource will be
* inflated, adding all top-level views to the activity.
*
* @param layoutResID Resource ID to be inflated.
*
* @see #setContentView(android.view.View)
* @see #setContentView(android.view.View, android.view.ViewGroup.LayoutParams)
*/
public void setContentView(@LayoutRes int layoutResID) {
getWindow().setContentView(layoutResID);
initWindowDecorActionBar();
}
/**
* Set the activity content to an explicit view. This view is placed
* directly into the activity's view hierarchy. It can itself be a complex
* view hierarchy. When calling this method, the layout parameters of the
* specified view are ignored. Both the width and the height of the view are
* set by default to {@link ViewGroup.LayoutParams#MATCH_PARENT}. To use
* your own layout parameters, invoke
* {@link #setContentView(android.view.View, android.view.ViewGroup.LayoutParams)}
* instead.
*
* @param view The desired content to display.
*
* @see #setContentView(int)
* @see #setContentView(android.view.View, android.view.ViewGroup.LayoutParams)
*/
public void setContentView(View view) {
getWindow().setContentView(view);
initWindowDecorActionBar();
}
/**
* Set the activity content to an explicit view. This view is placed
* directly into the activity's view hierarchy. It can itself be a complex
* view hierarchy.
*
* @param view The desired content to display.
* @param params Layout parameters for the view.
*
* @see #setContentView(android.view.View)
* @see #setContentView(int)
*/
public void setContentView(View view, ViewGroup.LayoutParams params) {
getWindow().setContentView(view, params);
initWindowDecorActionBar();
}
這裡面存在著3個重載函數,而不管你調用哪一個,最後都會調用到initWindowDecorActionBar()這個方法。
而對於新的一個AppcompatActivity,這個Activity裡面包含了一些新特性,現在我做的項目裡基本都是使用AppcompatActivity代替掉原來的Activity,當然也並不是一定的,還是要根據項目的實際情況來選擇。
在AppcompatActivity中,setContentView是這樣的:
@Override
public void setContentView(@LayoutRes int layoutResID) {
getDelegate().setContentView(layoutResID);
}
@Override
public void setContentView(View view) {
getDelegate().setContentView(view);
}
@Override
public void setContentView(View view, ViewGroup.LayoutParams params) {
getDelegate().setContentView(view, params);
}
一樣的3個重載函數,只是裡面沒有了上面的那個init方法,取而代之的是一個getDelegate().setContentView,這個delegate從字面上可以了解到它是一個委托的對象,源碼是這樣的:
/**
* @return The {@link AppCompatDelegate} being used by this Activity.
*/
@NonNull
public AppCompatDelegate getDelegate() {
if (mDelegate == null) {
mDelegate = AppCompatDelegate.create(this, this);
}
return mDelegate;
}
而在AppCompatDelegate.Create方法中,則會返回一個很有意思的東西:
/**
* Create a {@link android.support.v7.app.AppCompatDelegate} to use with {@code activity}.
*
* @param callback An optional callback for AppCompat specific events
*/
public static AppCompatDelegate create(Activity activity, AppCompatCallback callback) {
return create(activity, activity.getWindow(), callback);
}
private static AppCompatDelegate create(Context context, Window window,
AppCompatCallback callback) {
final int sdk = Build.VERSION.SDK_INT;
if (sdk >= 23) {
return new AppCompatDelegateImplV23(context, window, callback);
} else if (sdk >= 14) {
return new AppCompatDelegateImplV14(context, window, callback);
} else if (sdk >= 11) {
return new AppCompatDelegateImplV11(context, window, callback);
} else {
return new AppCompatDelegateImplV7(context, window, callback);
}
}
這裡會根據SDK的等級來返回不同的東西,這樣的話就不深究了,底層的話我撇了一下,應該原理和Activity是一樣的,可能存在一些區別。這裡就用Activity來談談它的setContentView方法做了什麼事。
在setContentView上面有段注釋:
Set the activity content from a layout resource. The resource will be inflated, adding all top-level views to the activity.
這裡就介紹了它的功能,它會按照一個布局資源去設置Activity的內容,而這個布局資源將會被引入然後添加所有頂級的Views到這個Activity當中。
這是個啥意思勒。
下面從網上扒了一張圖:

這裡是整個Activity的層級,最外面一層是我們的Activity,它包含裡面的所有東西。
再上一層是一個PhoneWindow,這個PhoneWindow是由Window類派生出來的,每一個PhoneWindow中都含有一個DecorView對象,Window是一個抽象類。
再上面一層就是一個DecorView,我理解這個DecorView就是一個ViewGroup,就是裝View的。
而在DecoreView中,最上面的View就是我們的TitleActionBar,下面就是我們要設置的content。所以在上面的initWindowDecZ喎?http://www.Bkjia.com/kf/ware/vc/" target="_blank" class="keylink">vckFjdGlvbkJhcr7NxNyywrW9ysfKssO00uLLvMHLsMmhozwvcD4NCjxwPrb41Nppbml0V2luZG93RGVjb3JBY3Rpb25CYXK3vbeo1tCjrNPQ0ru2zrT6wuujujwvcD4NCjxwcmUgY2xhc3M9"brush:java;">
/**
* Creates a new ActionBar, locates the inflated ActionBarView,
* initializes the ActionBar with the view, and sets mActionBar.
*/
private void initWindowDecorActionBar() {
Window window = getWindow();
// Initializing the window decor can change window feature flags.
// Make sure that we have the correct set before performing the test below.
window.getDecorView();
if (isChild() || !window.hasFeature(Window.FEATURE_ACTION_BAR) || mActionBar != null) {
return;
}
mActionBar = new WindowDecorActionBar(this);
mActionBar.setDefaultDisplayHomeAsUpEnabled(mEnableDefaultActionBarUp);
mWindow.setDefaultIcon(mActivityInfo.getIconResource());
mWindow.setDefaultLogo(mActivityInfo.getLogoResource());
}
注意上面的window.getDecoreView()方法的注釋,該方法會設置一些window的標志位,而當這個方法執行完之後,就再也不能更改了,這也就是為什麼很多第三方SDK設置window的標志位時一定要求要在setContentView方法前調用。
我們通過一個findViewById方法可以實現對象的綁定,那它底層究竟是怎麼實現的呢?
findViewById根據繼承的Activity類型的不同也存在著區別,老規矩,還是以Activity的來。
/**
* Finds a view that was identified by the id attribute from the XML that
* was processed in {@link #onCreate}.
*
* @return The view if found or null otherwise.
*/
@Nullable
public View findViewById(@IdRes int id) {
return getWindow().findViewById(id);
}
從源碼來看,findViewById也是經過了一層層的調用,它的功能如同它上面的注釋一樣,通過一個view的id屬性查找view,這裡也可以看到一個熟悉的getWindow方法,說明findViewById()實際上Activity把它也是交給了自己的window來做
/**
* Finds a view that was identified by the id attribute from the XML that
* was processed in {@link android.app.Activity#onCreate}. This will
* implicitly call {@link #getDecorView} for you, with all of the
* associated side-effects.
*
* @return The view if found or null otherwise.
*/
@Nullable
public View findViewById(@IdRes int id) {
return getDecorView().findViewById(id);
}
而在這裡面,又調用了getDecorView的findViewById()方法,這也相當於是一個層層傳遞的過程,因為DecorView我理解為就是一個ViewGroup,而當運行getDecorView().findViewById()方法時,就會運行View裡面的findViewById方法。它會使用這個被給予的id匹配子View的Id,如果匹配,就返回這個View,完成View的綁定
<CODE class="language-java hljs ">/**
* Look for a child view with the given id. If this view has the given
* id, return this view.
*
* @param id The id to search for.
* @return The view that has the given id in the hierarchy or null
*/
@Nullable
public final View findViewById(@IdRes int id) {
if (id < 0) {
return null;
}
return findViewTraversal(id);
}
/**
* {@hide}
* @param id the id of the view to be found
* @return the view of the specified id, null if cannot be found
*/
protected View findViewTraversal(@IdRes int id) {
if (id == mID) {
return this;
}
return null;
}</CODE>
最後總結一下(Activity中),findViewById的過程是這樣的:
Activity -> Window -> DecorView -> View
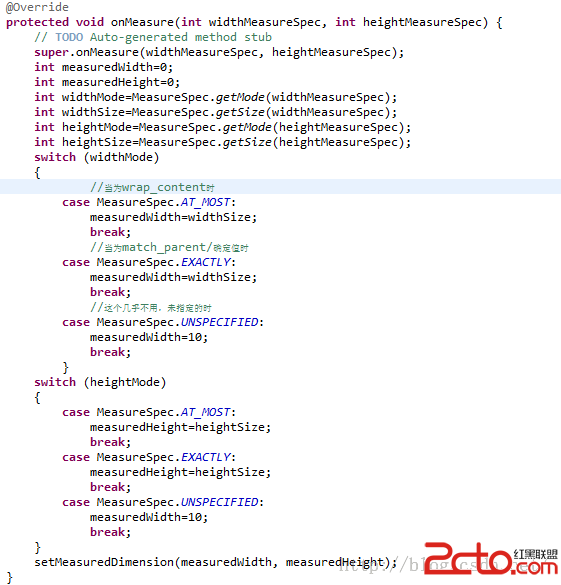 Android MeasuerSpce的由來及使用
Android MeasuerSpce的由來及使用
Android MeasuerSpce的由來及使用 含義:MeasuerSpce是parent傳遞給child的一組測量值(size)和模式(mode)的組合。 使用場景
 Win10 下使用 ionic 框架開發 android 應用之搭載開發環境,win10ionic
Win10 下使用 ionic 框架開發 android 應用之搭載開發環境,win10ionic
Win10 下使用 ionic 框架開發 android 應用之搭載開發環境,win10ionic轉載請注明出處:http://www.cnblogs.com/titib
 一個難倒 3年 android開發經驗 " 工程師 " 的 "bug"
一個難倒 3年 android開發經驗 " 工程師 " 的 "bug"
一個難倒 3年 android開發經驗 " 工程師 " 的 "bug" 一個關於 imageView 設置 sc
 百度地圖定位簽到功能,百度地圖簽到
百度地圖定位簽到功能,百度地圖簽到
百度地圖定位簽到功能,百度地圖簽到 1. 注意 key 一定要在activity 前面 <application android:allowBackup=tr