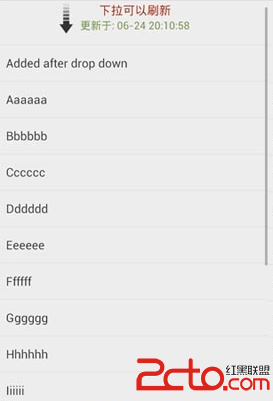
編輯:關於android開發
Unicode符號范圍 (一個字符兩個字節) | UTF-8編碼方式
(十六進制) | (二進制)
—————————————————————–
這兒有四個字節
從-----00 00 00 00---到----00 00 00 7F | 0xxxxxxx 一個字符需要一個字節
從-----00 00 00 80---到----00 00 07 FF | 110xxxxx 10xxxxxx 一個字符需要兩個字節
從-----00 00 08 00---到----00 00 FF FF | 1110xxxx 10xxxxxx 10xxxxxx 一個字符需要三個字節
從-----00 01 00 00---到----00 10 FF FF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 一個字符需要四個字節
I 0049
t 0074
' 0027
s 0073
0020
知 77e5
乎 4e4e
日 65e5
報 62a5
I 00000000 01001001
t 00000000 01110100
' 00000000 00100111
s 00000000 01110011
00000000 00100000
知 01110111 11100101
乎 01001110 01001110
日 01100101 11100101
報 01100010 10100101
I 01001001
t 01110100
' 00100111
s 01110011
00100000
知 11100111 10011111 10100101
乎 11100100 10111001 10001110
日 11100110 10010111 10100101
報 11100110 10001010 10100101
例子一:
String s ="abc中文喆镕";
byte[] a;
a=s.getBytes();
System.out.println("默認:"+Arrays.toString(a));
a=s.getBytes("GBK");
System.out.println("GBK:"+Arrays.toString(a));
a=s.getBytes("UTF-8");
System.out.println("UTF-8:"+Arrays.toString(a));
輸出:
默認:[97, 98, 99, -42, -48, -50, -60, -122, -76, -23, 70]
GBK:[97, 98, 99, -42, -48, -50, -60, -122, -76, -23, 70]
UTF-8:[97, 98, 99, -28, -72, -83, -26, -106, -121, -27, -106, -122, -23, -107, -107]
例子二:
String s;
byte[] a;
a=new byte[]{97, 98, 99, -42, -48, -50, -60, -122, -76, -23, 70};
s=new String(a);
System.out.println(s);
a=new byte[]{97, 98, 99, -42, -48, -50, -60, -122, -76, -23, 70};
s=new String(a,"GBK");
System.out.println(s);
a=new byte[]{97, 98, 99, -42, -48, -50, -60, -122, -76, -23, 70};
s=new String(a,"UTF-8");
System.out.println(s);
a=new byte[]{97, 98, 99, -28, -72, -83, -26, -106, -121, -27, -106, -122, -23, -107, -107};
s=new String(a,"UTF-8");
System.out.println(s);
輸出:
abc中文喆镕
abc中文喆镕
abc??????
abc中文喆镕
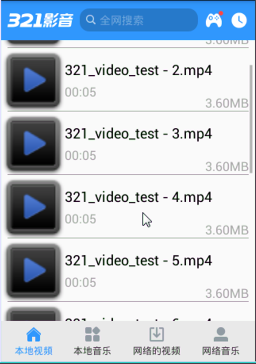 手機影音3--本地視頻列表,影音3--列表
手機影音3--本地視頻列表,影音3--列表
手機影音3--本地視頻列表,影音3--列表 1.寫布局 相對布局 : ListView和TextView和ProgressBar,初始化 1 <?xml ve
 android不太常用的控件,
android不太常用的控件,
android不太常用的控件,AutoCompleteTextView:是一種與EditText類似的視圖(實際上他是EditText的子類),只不過它還在用戶輸入時自動
 Android快樂貪吃蛇游戲實戰項目開發教程-02虛擬方向鍵(一)自定義控件概述,android-02
Android快樂貪吃蛇游戲實戰項目開發教程-02虛擬方向鍵(一)自定義控件概述,android-02
Android快樂貪吃蛇游戲實戰項目開發教程-02虛擬方向鍵(一)自定義控件概述,android-02該系列教程概述與目錄:http://www.cnblogs.com/
 Android面試題--事件處理,android試題--事件
Android面試題--事件處理,android試題--事件
Android面試題--事件處理,android試題--事件1、Handler 機制 Android 中主線程也叫 UI 線程,那麼從名字上我們也知道主線程主要是用來創建