編輯:關於Android編程
內存映射文件原理
首先說說這篇文章要解決什麼問題?
1.虛擬內存與內存映射文件的區別與聯系.
2.內存映射文件的原理.
3.內存映射文件的效率.
4.傳統IO和內存映射效率對比.
虛擬內存與內存映射文件的區別與聯系
二者的聯系
虛擬內存和內存映射文件都是將一部分內容加載到,另一部分放在磁盤上的一種機制,二者都是應用程序動態性的基礎,由於二者的虛擬性,對於用戶都是透明的.
虛擬內存其實就是硬盤的一部分,是計算機RAM與硬盤的數據交換區,因為實際的物理內存可能遠小於進程的地址空間,這就需要把內存中暫時不用到的數據放到硬盤上一個特殊的地方,當請求的數據不在內存中時,系統產生卻頁中斷,內存管理器便將對應的內存頁重新從硬盤調入物理內存。
內存映射文件是由一個文件到一塊內存的映射,使應用程序可以通過內存指針對磁盤上的文件進行訪問,其過程就如同對加載了文件的內存的訪問,因此內存文件映射非常適合於用來管理大文件。
二者的區別
1.虛擬內存使用硬盤只能是頁面文件,而內存映射使用的磁盤部分可以是任何磁盤文件.
2.二者的架構不同,或者是說應用的場景不同,虛擬內存是架構在物理內存之上,其引入是因為實際的物理內存運行程序所需的空間,即使現在計算機中的物理內存越來越大,程序的尺寸也在增長。將所有運行著的程序全部加載到內存中不經濟也非常不現實。內存映射文件架構在程序的地址空間之上,32位機地址空間只有4G,而某些大文件的尺寸可要要遠超出這個值,因此,用地址空間中的某段應用文件中的一部分可解決處理大文件的問題,在32中,使用內存映射文件可以處理2的64次(64EB)大小的文件.原因內存映射文件,除了處理大文件,還可用作進程間通信。
內存映射文件的原理
“映射”就是建立一種對應關系,在這裡主要是指硬盤上文件的位置與進程邏輯地址空間中一塊相同區域之間一一對應,這種關系純屬是邏輯上的概念,物理上是不存在的,原因是進程的邏輯地址空間本身就是不存在的,在內存映射過程中,並沒有實際的數據拷貝,文件沒有被載入內存,只是邏輯上放入了內存,具體到代碼,就是建立並初始化了相關的數據結構,這個過程有系統調用mmap()實現,所以映射的效率很高.
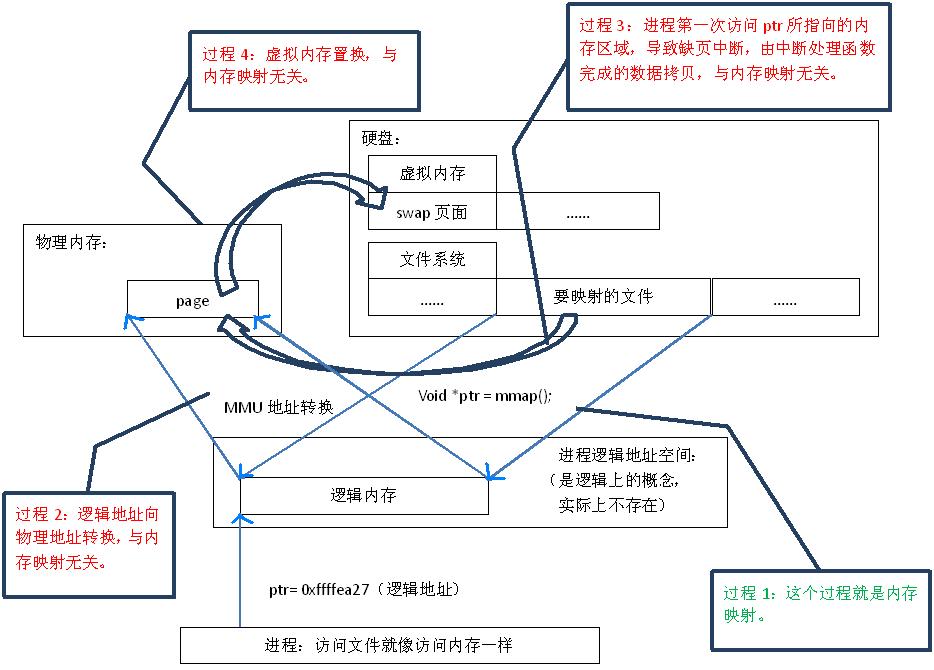
內存映射原理
上面說到建立內存映射沒有進行實際的數據拷貝,那麼進行進程又怎麼能最終通過內存操作訪問到硬盤上的文件呢?
看上圖:
1.調用mmap(),相當於要給進行內存映射的文件分配了虛擬內存,它會返回一個指針ptr,這個ptr所指向的是一個邏輯地址,要操作其中的數據,必須通過MMU將邏輯地址轉換成物理地址,如圖1中過程2所示。
2.建立內存映射並沒有實際拷貝數據,這時,MMU在地址映射表中是無法找到與ptr相對應的物理地址的,也就是MMU失敗,將產生一個缺頁中斷,缺 頁中斷的中斷響應函數會在swap中尋找相對應的頁面,如果找不到(也就是該文件從來沒有被讀入內存的情況),則會通過mmap()建立的映射關系,從硬 盤上將文件讀取到物理內存中,如圖1中過程3所示。
3.如果在拷貝數據時,發現物理內存不夠用,則會通過虛擬內存機制(swap)將暫時不用的物理頁面交換到硬盤上,如圖1中過程4所示。
內存映射文件的效率
了解過內存映射文件都知道,它比傳統的IO讀寫數據快很多,那麼,它為什麼會這麼快,從代碼層面上來看,從硬盤上將文件讀入內存,都是要經過數據拷貝,並且數據拷貝操作是由文件系統和硬件驅動實現的,理論上來說,拷貝數據的效率是一 樣的。其實,原因是read()是系統調用,其中進行了數據 拷貝,它首先將文件內容從硬盤拷貝到內核空間的一個緩沖區,如圖2中過程1,然後再將這些數據拷貝到用戶空間,如圖2中過程2,在這個過程中,實際上完成 了兩次數據拷貝 ;而mmap()也是系統調用,如前所述,mmap()中沒有進行數據拷貝,真正的數據拷貝是在缺頁中斷處理時進行的,由於mmap()將文件直接映射到用戶空間,所以中斷處理函數根據這個映射關系,直接將文件從硬盤拷貝到用戶空間,只進行了 一次數據拷貝 。因此,內存映射的效率要比read/write效率高。
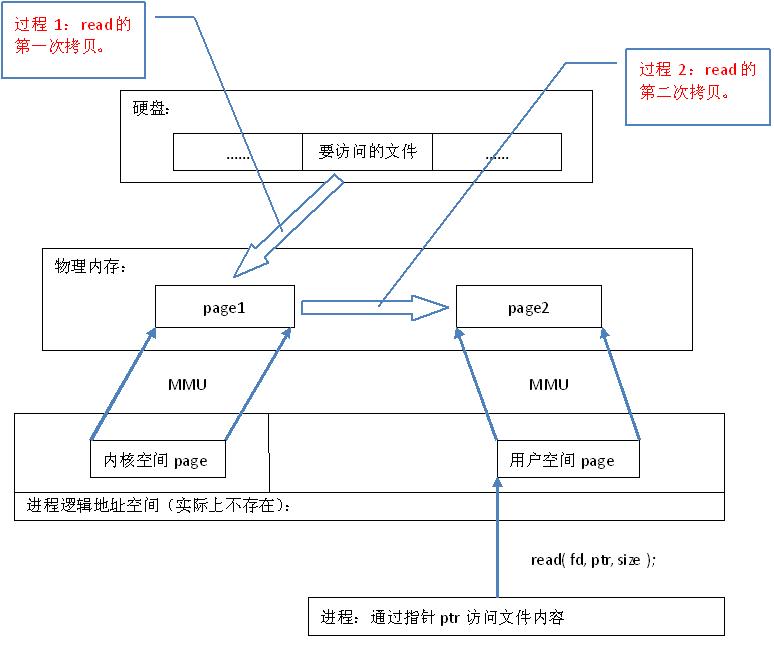
read系統調用原理
傳統IO和內存映射效率對比.
在這裡,使用java傳統的IO,加緩沖區的IO,內存映射分別讀取10M數據.用時如下:
public class MapBufDelete {
public static void main(String[] args) {
try {
FileInputStream fis=new FileInputStream("./largeFile.txt");
int sum=0;
int n;
long t1=System.currentTimeMillis();
try {
while((n=fis.read())>=0){
// 數據處理
}
} catch (IOException e) {
e.printStackTrace();
}
long t=System.currentTimeMillis()-t1;
System.out.println("傳統IOread文件,不使用緩沖區,用時:"+t);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
try {
FileInputStream fis=new FileInputStream("./largeFile.txt");
BufferedInputStream bis=new BufferedInputStream(fis);
int sum=0;
int n;
long t1=System.currentTimeMillis();
try {
while((n=bis.read())>=0){
// 數據處理
}
} catch (IOException e) {
e.printStackTrace();
}
long t=System.currentTimeMillis()-t1;
System.out.println("傳統IOread文件,使用緩沖區,用時:"+t);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
MappedByteBuffer buffer=null;
try {
buffer=new RandomAccessFile("./largeFile.txt","rw").getChannel().map(FileChannel.MapMode.READ_WRITE, 0, 1253244);
int sum=0;
int n;
long t1=System.currentTimeMillis();
for(int i=0;i<1024*1024*10;i++){
// 數據處理
}
long t=System.currentTimeMillis()-t1;
System.out.println("內存映射文件讀取文件,用時:"+t);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
}
}
}
運行結果
傳統IOread文件,不使用緩沖區,用時:4739
傳統IOread文件,使用緩沖區,用時:59
內存映射文件讀取文件,用時:11
最後,解釋一下,為什麼使用緩沖區讀取文件會比不使用快:
原因是每次進行IO操作,都要從用戶態陷入內核態,由內核把數據從磁盤中讀到內核緩沖區,再由內核緩沖區到用戶緩沖區,如果沒有buffer,讀取都需要從用戶態到內核態切換,而這種切換很耗時,所以,采用預讀,減少IO次數,如果有buffer,根據局部性原理,就會一次多讀數據,放到緩沖區中,減少了IO次數.
感謝閱讀,希望能幫助到大家,謝謝大家對本站的支持!
 Android實現字母雨的效果
Android實現字母雨的效果
首先來看效果: 一、實現原理在實現過程中,主要考慮整個界面由若干個字母組成的子母線條組成,這樣的話把固定數量的字母封裝成一個字母線條,而每個字母又封裝成一個對象,這樣的話
 解決努比亞nubia線刷提示Modem內部版本不匹配
解決努比亞nubia線刷提示Modem內部版本不匹配
有很多機油刷了miui後恢復的時候經常會遇到:檢查modem內部版本失敗 modem內部版本不匹配。遇到這種情況解決方法很簡單,下面來分享下經驗:找到線刷工
 Android SwipeMenuListView框架詳解分析
Android SwipeMenuListView框架詳解分析
周末 特地把Android SwipeMenuListView(滑動菜單)的知識資料整理一番,以下是整理內容:SwipeMenuListView(滑動菜單)A swipe
 Android畫廊效果之ViewPager顯示多個圖片
Android畫廊效果之ViewPager顯示多個圖片
首先來看下ViewPager顯示多個圖片效果:從上面的圖片可以看到,當添加多張圖片的時候,能夠在下方形成一個畫廊的效果,我們左右拉動圖片來看我們添加進去的圖片,效果是不是