編輯:關於Android編程
最近在項目中遇到了一個解析XML的問題,我們是用android自帶的DOM解析器來解析XML的,但發現了一個android的問題,那就是在2.3的SDK上面,無法解析像<, >, 等字符串。
盡管我們從服務器端返回的數據中,應該是不能包含< >這樣的字符,應該使用轉義,但有時候,由於歷史原因,導致服務器端不能作這樣的修正,所以這樣的問只能是在客戶端來解決了。下面我就說一說我們是如何解決這種問的。
1,現象
我們的解析代碼是:
[java] DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document documnet = builder.parse(in);
Element root = documnet.getDocumentElement();
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document documnet = builder.parse(in);
Element root = documnet.getDocumentElement();其中builder.parse(in)中的in是一個InputStream類型的輸入流,例如有如下一段XML:
[html] <?xml version="1.0" ?>
<data>
<success>1</success>
<error>
<code></code>
<message></message>
</error>
<result>
<history_info_list>
<row>
<purchase_info_id>dnrxmauxecj3z6e4</purchase_info_id>
<title_id>134051</title_id>
<title>まもって守護月天!再逢<Retrouvailles></title>
<volume_number>001</volume_number>
<author_name>桜野みねね</author_name>
<contents_name>まもって守護月天!再逢<Retrouvailles> 1巻</contents_name>
<date_open>2011-12-02</date_open>
<purchase_date>2012-02-06 18:39:48</purchase_date>
<image_url>/resources/c_media/images/thumb/262/134051_01_1_L.jpg</image_url>
<contents>
<story_number>1</story_number>
<contents_id>BT000013405100100101500014</contents_id>
<file_size>34168162</file_size>
<Within_Wifi>0</Within_Wifi>
</contents>
<text_to_speech_flg>0</text_to_speech_flg>
<restrict_num>-1</restrict_num>
<issue>3</issue>
<subscription>0</subscription>
<adult_flg>0</adult_flg>
</row>
</history_info_list>
</result>
</data>
<?xml version="1.0" ?>
<data>
<success>1</success>
<error>
<code></code>
<message></message>
</error>
<result>
<history_info_list>
<row>
<purchase_info_id>dnrxmauxecj3z6e4</purchase_info_id>
<title_id>134051</title_id>
<title>まもって守護月天!再逢<Retrouvailles></title>
<volume_number>001</volume_number>
<author_name>桜野みねね</author_name>
<contents_name>まもって守護月天!再逢<Retrouvailles> 1巻</contents_name>
<date_open>2011-12-02</date_open>
<purchase_date>2012-02-06 18:39:48</purchase_date>
<image_url>/resources/c_media/images/thumb/262/134051_01_1_L.jpg</image_url>
<contents>
<story_number>1</story_number>
<contents_id>BT000013405100100101500014</contents_id>
<file_size>34168162</file_size>
<Within_Wifi>0</Within_Wifi>
</contents>
<text_to_speech_flg>0</text_to_speech_flg>
<restrict_num>-1</restrict_num>
<issue>3</issue>
<subscription>0</subscription>
<adult_flg>0</adult_flg>
</row>
</history_info_list>
</result>
</data>
其中有一個title結點,中間包含< >,但是XML中已經用了轉義,所以應該是能正常解析出來的,但在SDK2.3(准確說來應該是3.0以下),它對這些轉義字符作了特殊處理,它會把title中間文字當成四個文本結點,其內容分別是:
1, まもって守護月天!再逢
2, <
3, Retrouvailles
4, > 1巻
所以,這是不正確的,其實它應該就是一個節點,內容是[ まもって守護月天!再逢<Retrouvailles> 1巻 ]。不過在3.0的SDK,這種問題被修正了。
2,問題的原因
好,上面說的是現象,我們現在說一下造成這種現象的原因及解決辦法。
翻看android源碼發現:
android的XML解析實現用的是apache harmony代碼,我想android的dalvik應該就是apache的harmonyxml parser,這個沒有深究。
而實際上harmony的XML解析用的又是KXML,看來android就是一堆開源的代碼疊加起來的。
[java] 113行: XmlPullParser parser = new KXmlParser();
265行:else if (token == XmlPullParser.TEXT)
node.appendChild(document.createTextNode(parser.getText()));
277行:else if (token == XmlPullParser.ENTITY_REF)
String entity = parser.getName(); if (entityResolver != null) {
// TODO Implement this...
} String replacement = resolveStandardEntity(entity);
if (replacement != null) {
node.appendChild(document.createTextNode(replacement));
} else {
node.appendChild(document.createEntityReference(entity));
}
113行: XmlPullParser parser = new KXmlParser();
265行:else if (token == XmlPullParser.TEXT)
node.appendChild(document.createTextNode(parser.getText()));
277行:else if (token == XmlPullParser.ENTITY_REF)
String entity = parser.getName(); if (entityResolver != null) {
// TODO Implement this...
} String replacement = resolveStandardEntity(entity);
if (replacement != null) {
node.appendChild(document.createTextNode(replacement));
} else {
node.appendChild(document.createEntityReference(entity));
}從上面可以看到,處理帶有&<>&;這些字符時,分成了幾段文本節點。
3,解決方案
問題的原因我們已經知道了,怎麼解決呢?
1,判斷一下,如果子結點全是文本結點的話,把結點的所有文本字符串拼起來。
2,更改上面的處理方法,node.appendChild這行代碼,當發現這個節點的第一個子節點是文本節點時,把當前字符加上去。
在項目中所采用的方法是第一種,因為這方法簡單,實現如下:
[java] /**
* This method is used to indicate the specified node's all sub nodes are text node or not.
*
* @param node The specified node.
*
* @return true if all sub nodes are text type, otherwise false.
*/
public static boolean areAllSubNodesTextType(Node node)
{
if (null != node)
{
int nodeCount = node.getChildNodes().getLength();
NodeList list = node.getChildNodes();
for (int i = 0; i < nodeCount; ++i)
{
short noteType = list.item(i).getNodeType();
if (Node.TEXT_NODE != noteType)
{
return false;
}
}
}
return true;
}
/**
* Get the node value. If the node's all sub nodes are text type, it will append
* all sub node's text as a whole text and return it.
*
* @param node The specified node.
*
* @return The value.
*/
private static String getNodeValue(Node node)
{
if (null == node)
{
return "";
}
StringBuffer sb = new StringBuffer();
int nodeCount = node.getChildNodes().getLength();
NodeList list = node.getChildNodes();
for (int i = 0; i < nodeCount; ++i)
{
short noteType = list.item(i).getNodeType();
if (Node.TEXT_NODE == noteType)
{
sb.append(list.item(i).getNodeValue());
}
}
return sb.toString();
}
}
/**
* This method is used to indicate the specified node's all sub nodes are text node or not.
*
* @param node The specified node.
*
* @return true if all sub nodes are text type, otherwise false.
*/
public static boolean areAllSubNodesTextType(Node node)
{
if (null != node)
{
int nodeCount = node.getChildNodes().getLength();
NodeList list = node.getChildNodes();
for (int i = 0; i < nodeCount; ++i)
{
short noteType = list.item(i).getNodeType();
if (Node.TEXT_NODE != noteType)
{
return false;
}
}
}
return true;
}
/**
* Get the node value. If the node's all sub nodes are text type, it will append
* all sub node's text as a whole text and return it.
*
* @param node The specified node.
*
* @return The value.
*/
private static String getNodeValue(Node node)
{
if (null == node)
{
return "";
}
StringBuffer sb = new StringBuffer();
int nodeCount = node.getChildNodes().getLength();
NodeList list = node.getChildNodes();
for (int i = 0; i < nodeCount; ++i)
{
short noteType = list.item(i).getNodeType();
if (Node.TEXT_NODE == noteType)
{
sb.append(list.item(i).getNodeValue());
}
}
return sb.toString();
}
}
 Android Studio導入項目的幾種方法
Android Studio導入項目的幾種方法
本篇教程中使用到的Android Studio版本為1.0, Eclipse ADT版本23.0.4。請嘗試更新到該版本。Android Studio默認使用 Gradl
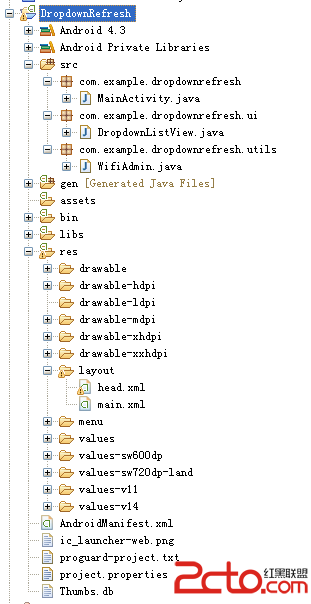 Android常用控件之下拉刷新Wifi列表
Android常用控件之下拉刷新Wifi列表
有些列表信息需要手動去更新,此時比較常用的就是下拉刷新列表,在這裡就使用下拉列表來刷新當前Wifi信息 目錄結構 界面 關鍵代碼 下拉列表類 p
 Android Activity之間傳遞圖片(Bitmap)的方法
Android Activity之間傳遞圖片(Bitmap)的方法
在Android開發中;Activity之間傳遞參數是常見的事;如果我們要在Activity之間傳遞圖片;1。MainActivity中包括一個ImageView;當我們
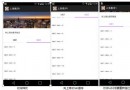 Android Listview多tab上滑懸浮效果
Android Listview多tab上滑懸浮效果
樣例 近期要做一個含有兩個tab切換頁面,兩個頁面有公共的描述信息區域,兩個tab都是listvi