編輯:關於Android編程
首先,fence的產生和GPU有很大的關系,下面是wiki上GPU的介紹。
A graphics processing unit (GPU), also occasionally called visual processing unit (VPU), is a specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display. GPUs are used in embedded systems, mobile phones, personal computers, workstations, and game consoles. Modern GPUs are very efficient at manipulating computer graphics and image processing, and their highly parallel structure makes them more effective than general-purpose CPUs for algorithms where the processing of large blocks of visual data is done in parallel.
GPU的產生就是為了加速圖形顯示到display的過程。現在廣泛使用在嵌入式設備,手機,pc,服務器,游戲機等上。GPU在圖形處理上非常高效,此外它的並行架構使得在處理大規模的並行數據上性能遠超CPU,以前上學的時候做過CUDA相關的東西,印象很深,對於並行數據處理能力提升了起碼10倍。
而CPU和GPU兩個硬件是異步的,當使用opengl時,首先在CPU上調用一系列gl命令,然後這些命令去GPU執行真正的繪圖過程,繪圖何時結束,CPU根本不知道,當然可以讓CPU阻塞等待GPU繪圖完成,然後再去處理後續工作,但是這樣效率就太低了。
下面的例子非常形象,說明了fence在GPU和CPU之間協調工作,fence讓GPU和CPU並行運行,提高了圖像顯示的速度。
For example, an application may queue up work to be carried out in the GPU. The GPU then starts drawing that image. Although the image hasn’t been drawn into memory yet, the buffer pointer can still be passed to the window compositor along with a fence that indicates when the GPU work will be finished. The window compositor may then start processing ahead of time and hand off the work to the display controller. In this manner, the CPU work can be done ahead of time. Once the GPU finishes, the display controller can immediately display the image.
一般fence的使用方法如下,
//首先創建一個EGLSyncKHR 同步對象
EGLSyncKHR sync = eglCreateSyncKHR(dpy,
EGL_SYNC_NATIVE_FENCE_ANDROID, NULL);
if (sync == EGL_NO_SYNC_KHR) {
ST_LOGE("syncForReleaseLocked: error creating EGL fence: %#x",
eglGetError());
return UNKNOWN_ERROR;
}
//將opengl cmd 緩沖隊列中的cmd全部flush去執行,而不用去等cmd緩沖區滿了再執行
glFlush();
//將同步對象sync轉換為fencefd
int fenceFd = eglDupNativeFenceFDANDROID(dpy, sync);
eglDestroySyncKHR(dpy, sync);
if (fenceFd == EGL_NO_NATIVE_FENCE_FD_ANDROID) {
ST_LOGE("syncForReleaseLocked: error dup'ing native fence "
"fd: %#x", eglGetError());
return UNKNOWN_ERROR;
}
//利用fencefd,新建一個fence對象
sp fence(new Fence(fenceFd));
//將新創建的fence和老的fence merge
status_t err = addReleaseFenceLocked(mCurrentTexture,
mCurrentTextureBuf, fence);
其中,addReleaseFenceLocked為
status_t ConsumerBase::addReleaseFenceLocked(int slot,
const sp graphicBuffer, const sp& fence) {
CB_LOGV("addReleaseFenceLocked: slot=%d", slot);
// If consumer no longer tracks this graphicBuffer, we can safely
// drop this fence, as it will never be received by the producer.
if (!stillTracking(slot, graphicBuffer)) {
return OK;
}
//老的fence為null,直接賦值
if (!mSlots[slot].mFence.get()) {
mSlots[slot].mFence = fence;
} else {
//否則執行merge
sp mergedFence = Fence::merge(
String8::format("%.28s:%d", mName.string(), slot),
mSlots[slot].mFence, fence);
if (!mergedFence.get()) {
CB_LOGE("failed to merge release fences");
// synchronization is broken, the best we can do is hope fences
// signal in order so the new fence will act like a union
mSlots[slot].mFence = fence;
return BAD_VALUE;
}
mSlots[slot].mFence = mergedFence;
}
return OK;
}
關於Fence對象,只有當mFenceFd不等於-1的時候才是有效的fence,即可以起到“攔截”作用,讓CPU和GPU進行同步。
//NO_FENCE對應的mFenceFd為-1
const sp Fence::NO_FENCE = sp(new Fence);
Fence::Fence() :
mFenceFd(-1) {
}
Fence::Fence(int fenceFd) :
mFenceFd(fenceFd) {
}
而Fence這個類,由於實現了Flattenable協議,所以可以利用binder傳遞。
Most recent Android devices support the “sync framework”. This allows the system to do some nifty thing when combined with hardware components that can manipulate graphics data asynchronously. For example, a producer can submit a series of OpenGL ES drawing commands and then enqueue the output buffer before rendering completes. The buffer is accompanied by a fence that signals when the contents are ready. A second fence accompanies the buffer when it is returned to the free list, so that the consumer can release the buffer while the contents are still in use. This approach improves latency and throughput as the buffers move through the system.
上面這段話結合BufferQueue的生產者和消費者模式更容易理解,描述了fence如何提升graphic的顯示性能。生產者利用opengl繪圖,不用等繪圖完成,直接queue buffer,在queue buffer的同時,需要傳遞給BufferQueue一個fence,而消費者acquire這個buffer後同時也會獲取到這個fence,這個fence在GPU繪圖完成後signal。這就是所謂的“acquireFence”,用於生產者通知消費者生產已完成。
當消費者對acquire到的buffer做完自己要做的事情後(例如把buffer交給surfaceflinger去合成),就要把buffer release到BufferQueue的free list,由於該buffer的內容可能正在被surfaceflinger使用,所以release時也需要傳遞一個fence,用來指示該buffer的內容是否依然在被使用,接下來生產者在繼續dequeue buffer時,如果dequeue到了這個buffer,在使用前先要等待該fence signal。這就是所謂的“releaseFence”,後者用於消費者通知生產者消費已完成。
一般來說,fence對象(new Fence)在一個BufferQueue對應的生產者和消費者之間通過binder傳遞,不會在不同的BufferQueue中傳遞(但是對利用overlay合成的layer,其所對應的acquire fence,會被傳遞到HWComposer中,因為overlay直接會由hal層的hwcomposer去合成,其使用的graphic buffer是上層surface中render的buffer,如果上層surface使用opengl合成,那麼在hwcomposer對overlay合成前先要保證render完成(畫圖完成),即在hwcomposer中等待這個fence觸發,所以fence需要首先被傳遞到hal層,但是這個fence的傳遞不是通過BufferQueue的binder傳遞,而是利用具體函數去實現,後續有分析)。
由於opengl的實現分為軟件和硬件,所以下面結合代碼分別分析。
opengl的軟件實現,也就是agl,雖然4.4上已經捨棄了,但是在一個項目中由於沒有GPU,overlay,所以只能使用agl去進行layer的合成。agl的eglCreateSyncKHR函數如下,其中的注釋寫的很清晰,agl是同步的,因為不牽扯GPU。所以通過agl創建的fence的mFenceFd都是-1。
EGLSyncKHR eglCreateSyncKHR(EGLDisplay dpy, EGLenum type,
const EGLint *attrib_list)
{
if (egl_display_t::is_valid(dpy) == EGL_FALSE) {
return setError(EGL_BAD_DISPLAY, EGL_NO_SYNC_KHR);
}
if (type != EGL_SYNC_FENCE_KHR ||
(attrib_list != NULL && attrib_list[0] != EGL_NONE)) {
return setError(EGL_BAD_ATTRIBUTE, EGL_NO_SYNC_KHR);
}
if (eglGetCurrentContext() == EGL_NO_CONTEXT) {
return setError(EGL_BAD_MATCH, EGL_NO_SYNC_KHR);
}
// AGL is synchronous; nothing to do here.
// agl是同步的
return FENCE_SYNC_HANDLE;
}
當有GPU時,opengl使用硬件實現,這時候需要有fence的同步,上層考慮兩種情況,下層使用opengl和overlay合成:
a, 上層使用canvas繪圖;
b, 上層使用opengl繪圖。
在http://blog.csdn.net/lewif/article/details/50946236中已經介紹了opengl函數結合egl的使用方法,下面對上層兩種情況展開分析。
在上層使用canvas繪圖時,先要使用lockCanvas去獲取一個Canvas,
/*--------------surface.java---------------------------*/
public Canvas lockCanvas(Rect inOutDirty)
throws Surface.OutOfResourcesException, IllegalArgumentException {
//這裡的mNativeObject就是native層的surface對象對應的指針
mLockedObject = nativeLockCanvas(mNativeObject, mCanvas, inOutDirty);
return mCanvas;
}
/*--------------android_view_Surface.cpp---------------------------*/
static jint nativeLockCanvas(JNIEnv* env, jclass clazz,
jint nativeObject, jobject canvasObj, jobject dirtyRectObj) {
//利用nativeObject指針還原surface對象
sp surface(reinterpret_cast(nativeObject));
ANativeWindow_Buffer outBuffer;
status_t err = surface->lock(&outBuffer, dirtyRectPtr);
}
繼續surface->lock,在lock函數中會去從BufferQueue中dequeue Buffer,其中在dequeue到後,先要去等待release fence觸發。
/*--------------Surface.cpp---------------------------*/
status_t Surface::lock(
ANativeWindow_Buffer* outBuffer, ARect* inOutDirtyBounds)
{
ANativeWindowBuffer* out;
int fenceFd = -1;
//使用dequeueBuffer從BufferQueue中獲取buffer,返回fencefd
//①該buffer slot如果是第一次dequeue到,對應的是NO_FENCE,fencefd為-1
//②但是,如果該buffer slot被使用過,release過,這時候buffer slot就伴隨個
// release fence用來指示該buffer的內容是否依然被使用,這時候dequeueBuffer返回的就是
// 對應的release fence,經過fence->dup(),fenceFd肯定不為-1了
status_t err = dequeueBuffer(&out, &fenceFd);
if (err == NO_ERROR) {
sp backBuffer(GraphicBuffer::getSelf(out));
//通過上面的release fencefd新建fence
sp fence(new Fence(fenceFd));
//dequeue後需要等待該buffer的內容不再使用了,才能去畫圖
//如果是第一次dequeue到,fenceFd為-1,直接返回,不阻塞等待
err = fence->waitForever("Surface::lock");
if (err != OK) {
ALOGE("Fence::wait failed (%s)", strerror(-err));
cancelBuffer(out, fenceFd);
return err;
}
return err;
}
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
sp fence;
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, mSwapIntervalZero,
reqW, reqH, mReqFormat, mReqUsage);
sp& gbuf(mSlots[buf].buffer);
if ((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == 0) {
result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);
return result;
}
}
//dequeue返回的release fence是否不為-1。
if (fence->isValid()) {
*fenceFd = fence->dup();
if (*fenceFd == -1) {
ALOGE("dequeueBuffer: error duping fence: %d", errno);
// dup() should never fail; something is badly wrong. Soldier on
// and hope for the best; the worst that should happen is some
// visible corruption that lasts until the next frame.
}
} else {
*fenceFd = -1;
}
*buffer = gbuf.get();
return OK;
}
通過上面的dequeueBuffer獲取到了buffer,也經過waitForever,release fence觸發了,該buffer可以用來畫圖了。Canvas的繪圖過程都是同步的(非硬件加速,底層由skcanvas實現)。繪圖完成後,會調用java層surface的unlockCanvasAndPost函數,最終會調用native層的unlockAndPost,函數中會調用queueBuffer,傳入的fencefd為-1,為何?引文canvas的繪圖是同步的,到這裡上層繪圖已經完成了,不需要acquire fence。
status_t Surface::unlockAndPost()
{
if (mLockedBuffer == 0) {
ALOGE("Surface::unlockAndPost failed, no locked buffer");
return INVALID_OPERATION;
}
status_t err = mLockedBuffer->unlock();
ALOGE_IF(err, "failed unlocking buffer (%p)", mLockedBuffer->handle);
//調用queueBuffer,fencefd為-1,因為canvas是同步繪圖的
err = queueBuffer(mLockedBuffer.get(), -1);
ALOGE_IF(err, "queueBuffer (handle=%p) failed (%s)",
mLockedBuffer->handle, strerror(-err));
mPostedBuffer = mLockedBuffer;
mLockedBuffer = 0;
return err;
}
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
ATRACE_CALL();
ALOGV("Surface::queueBuffer");
Mutex::Autolock lock(mMutex);
int64_t timestamp;
bool isAutoTimestamp = false;
if (mTimestamp == NATIVE_WINDOW_TIMESTAMP_AUTO) {
timestamp = systemTime(SYSTEM_TIME_MONOTONIC);
isAutoTimestamp = true;
ALOGV("Surface::queueBuffer making up timestamp: %.2f ms",
timestamp / 1000000.f);
} else {
timestamp = mTimestamp;
}
int i = getSlotFromBufferLocked(buffer);
if (i < 0) {
return i;
}
// Make sure the crop rectangle is entirely inside the buffer.
Rect crop;
mCrop.intersect(Rect(buffer->width, buffer->height), &crop);
//queueBuffer到BufferQueue中,帶了一個fencefd為-1的fence
sp fence(fenceFd >= 0 ? new Fence(fenceFd) : Fence::NO_FENCE);
IGraphicBufferProducer::QueueBufferOutput output;
IGraphicBufferProducer::QueueBufferInput input(timestamp, isAutoTimestamp,
crop, mScalingMode, mTransform, mSwapIntervalZero, fence);
status_t err = mGraphicBufferProducer->queueBuffer(i, input, &output);
return err;
}
通過Surface::queueBuffer已經將畫好的buffer queue進了BufferQueue。
在前面講過,opengl繪圖時先會用egl創建本地環境,然後調用gl相關繪圖命令,最後調用eglSwapBuffers()去queue和deque buffer。但是egl、opengl的具體實現和GPU硬件相關,硬件廠商一般都不會給我們提供源代碼,只有so庫,所以下面分析使用agl的實現代碼,只是為了說明fence的創建、傳遞以及wait。
eglCreateWindowSurface()函數,
/*--------------libagl\egl.java---------------------------*/
EGLSurface eglCreateWindowSurface( EGLDisplay dpy, EGLConfig config,
NativeWindowType window,
const EGLint *attrib_list)
{
return createWindowSurface(dpy, config, window, attrib_list);
}
static EGLSurface createWindowSurface(EGLDisplay dpy, EGLConfig config,
NativeWindowType window, const EGLint *attrib_list)
{
// egl_surface_t的具體實現為egl_window_surface_v2_t
egl_surface_t* surface;
surface = new egl_window_surface_v2_t(dpy, config, depthFormat,
static_cast(window));
return surface;
}
swapBuffers()會觸發dequeue和queue buffer,因為看不到具體實現代碼,所以只能通過抓log猜測實現。
EGLBoolean egl_window_surface_v2_t::swapBuffers()
{
unlock(buffer);
previousBuffer = buffer;
//在eglMakeCurrent中,會先去調用connect函數,其中會dequeue第一個buffer
//調用surface的queueBuffer,agl的實現fencefd輸入為-1
//通過抓取高通平台log,queue buffer後fencefd均不為-1,
//肯定在前面先創建了fence同步對象,經過merge後肯定不再為-1了
nativeWindow->queueBuffer(nativeWindow, buffer, -1);
buffer = 0;
// dequeue a new buffer
int fenceFd = -1;
//第一次被申請的buffer slot,返回-1
//如果不是,有release fence,則會dup該fencefd
if (nativeWindow->dequeueBuffer(nativeWindow, &buffer, &fenceFd) == NO_ERROR) {
sp fence(new Fence(fenceFd));
//wait,等待release fence觸發
if (fence->wait(Fence::TIMEOUT_NEVER)) {
nativeWindow->cancelBuffer(nativeWindow, buffer, fenceFd);
return setError(EGL_BAD_ALLOC, EGL_FALSE);
}
// reallocate the depth-buffer if needed
if ((width != buffer->width) || (height != buffer->height)) {
// TODO: we probably should reset the swap rect here
// if the window size has changed
width = buffer->width;
height = buffer->height;
if (depth.data) {
free(depth.data);
depth.width = width;
depth.height = height;
depth.stride = buffer->stride;
depth.data = (GGLubyte*)malloc(depth.stride*depth.height*2);
if (depth.data == 0) {
setError(EGL_BAD_ALLOC, EGL_FALSE);
return EGL_FALSE;
}
}
}
// keep a reference on the buffer
buffer->common.incRef(&buffer->common);
// finally pin the buffer down
if (lock(buffer, GRALLOC_USAGE_SW_READ_OFTEN |
GRALLOC_USAGE_SW_WRITE_OFTEN, &bits) != NO_ERROR) {
ALOGE("eglSwapBuffers() failed to lock buffer %p (%ux%u)",
buffer, buffer->width, buffer->height);
return setError(EGL_BAD_ACCESS, EGL_FALSE);
// FIXME: we should make sure we're not accessing the buffer anymore
}
} else {
return setError(EGL_BAD_CURRENT_SURFACE, EGL_FALSE);
}
return EGL_TRUE;
}
上面經過兩種不同的畫圖方式,經過queue buffer後:
a, canvas的acquire fencefd為-1,因為繪圖是異步的;
b, opengl的acquire fencefd肯定不為-1,因為opengl繪圖是異步的嘛;
layer中的SurfaceFlingerConsumer做為消費者(和surface對應),當queue buffer到BufferQueue時最終會觸發layer的onFrameAvailable()函數,而該函數會觸發一次surfaceflinger的vsync事件。
surfaceflinger在處理vsync信號的時候,執行handleMessageInvalidate()—>handlePageFlip()—>layer->latchBuffer(),在latchBuffer中首先會調用mSurfaceFlingerConsumer->updateTexImage(),
Region Layer::latchBuffer(bool& recomputeVisibleRegions)
{
ATRACE_CALL();
Region outDirtyRegion;
if (mQueuedFrames > 0) {
sp oldActiveBuffer = mActiveBuffer;
Reject r(mDrawingState, getCurrentState(), recomputeVisibleRegions);
//①調用updateTexImage
status_t updateResult = mSurfaceFlingerConsumer->updateTexImage(&r);
// update the active buffer
mActiveBuffer = mSurfaceFlingerConsumer->getCurrentBuffer();
if (mActiveBuffer == NULL) {
// this can only happen if the very first buffer was rejected.
return outDirtyRegion;
}
return outDirtyRegion;
}
在這裡面會去acquire buffer,然後acquire到的buffer就會去用來合成。主要做的事情:
a, acquire一個新的buffer;
b, 將上一次對應的buffer先release了,並為上次的buffer創建一個release fence,將該release fence傳遞給BufferQueue中的slot對應的mSlots[slot]的mFence;
c, 更新mCurrentTexture和mCurrentTextureBuf為這次acquire到的buffer以及slot。
目前acquire fencefd還沒使用,因為還未去合成這個layer,沒到用layer中數據的時候。
status_t SurfaceFlingerConsumer::updateTexImage(BufferRejecter* rejecter)
{
BufferQueue::BufferItem item;
// Acquire the next buffer.
// In asynchronous mode the list is guaranteed to be one buffer
// deep, while in synchronous mode we use the oldest buffer.
//① 首先acquireBuffer
// a, 如果上層canvas繪圖,獲取到的fencefd為-1
// b, 上層opengl繪圖,獲取到的fencefd不為-1
err = acquireBufferLocked(&item, computeExpectedPresent());
//② 每次只能處理一個graphic buffer,要將上一次對應的buffer先release了,供別人使用
//首先創建一個release fence,
//將release fence傳遞給BufferQueue中的slot對應的mSlots[slot]的mFence
// Release the previous buffer.
err = updateAndReleaseLocked(item);
//③ 4.4已經不走這個if了,會在Layer::onDraw中去創建紋理
if (!SyncFeatures::getInstance().useNativeFenceSync()) {
// Bind the new buffer to the GL texture.
//
// Older devices require the "implicit" synchronization provided
// by glEGLImageTargetTexture2DOES, which this method calls. Newer
// devices will either call this in Layer::onDraw, or (if it's not
// a GL-composited layer) not at all.
err = bindTextureImageLocked();
}
return err;
}
status_t GLConsumer::updateAndReleaseLocked(const BufferQueue::BufferItem& item)
{
int buf = item.mBuf;
// 如果mEglSlots[buf]對應的EGLImageKHR 沒創建,先創建
// If the mEglSlot entry is empty, create an EGLImage for the gralloc
// buffer currently in the slot in ConsumerBase.
//
// We may have to do this even when item.mGraphicBuffer == NULL (which
// means the buffer was previously acquired), if we destroyed the
// EGLImage when detaching from a context but the buffer has not been
// re-allocated.
if (mEglSlots[buf].mEglImage == EGL_NO_IMAGE_KHR) {
EGLImageKHR image = createImage(mEglDisplay,
mSlots[buf].mGraphicBuffer, item.mCrop);
mEglSlots[buf].mEglImage = image;
mEglSlots[buf].mCropRect = item.mCrop;
}
// 在釋放老的buffer前,先給添加一個release fence,有可能還在使用
// Do whatever sync ops we need to do before releasing the old slot.
err = syncForReleaseLocked(mEglDisplay);
// 先把老的buffer,release了
// 如果是第一次為mCurrentTexture為BufferQueue::INVALID_BUFFER_SLOT,-1
// 將release fence傳遞給BufferQueue中的slot對應的mSlots[slot]的mFence
// release old buffer
if (mCurrentTexture != BufferQueue::INVALID_BUFFER_SLOT) {
status_t status = releaseBufferLocked(
mCurrentTexture, mCurrentTextureBuf, mEglDisplay,
mEglSlots[mCurrentTexture].mEglFence);
if (status < NO_ERROR) {
ST_LOGE("updateAndRelease: failed to release buffer: %s (%d)",
strerror(-status), status);
err = status;
// keep going, with error raised [?]
}
}
//更新這次acquire到的buffer到mCurrentTexture和mCurrentTextureBuf
// Update the GLConsumer state.
mCurrentTexture = buf;
mCurrentTextureBuf = mSlots[buf].mGraphicBuffer;
mCurrentCrop = item.mCrop;
mCurrentTransform = item.mTransform;
mCurrentScalingMode = item.mScalingMode;
mCurrentTimestamp = item.mTimestamp;
//這個就是生產者傳過來的acquire fence
mCurrentFence = item.mFence;
mCurrentFrameNumber = item.mFrameNumber;
computeCurrentTransformMatrixLocked();
return err;
}
status_t GLConsumer::syncForReleaseLocked(EGLDisplay dpy) {
ST_LOGV("syncForReleaseLocked");
//只有第一次mCurrentTexture會為-1
//創建一個release fence
if (mCurrentTexture != BufferQueue::INVALID_BUFFER_SLOT) {
if (SyncFeatures::getInstance().useNativeFenceSync()) {
EGLSyncKHR sync = eglCreateSyncKHR(dpy,
EGL_SYNC_NATIVE_FENCE_ANDROID, NULL);
if (sync == EGL_NO_SYNC_KHR) {
ST_LOGE("syncForReleaseLocked: error creating EGL fence: %#x",
eglGetError());
return UNKNOWN_ERROR;
}
glFlush();
int fenceFd = eglDupNativeFenceFDANDROID(dpy, sync);
eglDestroySyncKHR(dpy, sync);
if (fenceFd == EGL_NO_NATIVE_FENCE_FD_ANDROID) {
ST_LOGE("syncForReleaseLocked: error dup'ing native fence "
"fd: %#x", eglGetError());
return UNKNOWN_ERROR;
}
sp fence(new Fence(fenceFd));
status_t err = addReleaseFenceLocked(mCurrentTexture,
mCurrentTextureBuf, fence);
if (err != OK) {
ST_LOGE("syncForReleaseLocked: error adding release fence: "
"%s (%d)", strerror(-err), err);
return err;
}
} else if (mUseFenceSync && SyncFeatures::getInstance().useFenceSync()) {
//不會走到這
}
return OK;
}
status_t ConsumerBase::addReleaseFenceLocked(int slot,
const sp graphicBuffer, const sp& fence) {
//給mSlots[slot].mFence添加fence
if (!mSlots[slot].mFence.get()) {
mSlots[slot].mFence = fence;
} else {
sp mergedFence = Fence::merge(
String8::format("%.28s:%d", mName.string(), slot),
mSlots[slot].mFence, fence);
if (!mergedFence.get()) {
CB_LOGE("failed to merge release fences");
// synchronization is broken, the best we can do is hope fences
// signal in order so the new fence will act like a union
mSlots[slot].mFence = fence;
return BAD_VALUE;
}
mSlots[slot].mFence = mergedFence;
}
return OK;
}
status_t GLConsumer::releaseBufferLocked(int buf,
sp graphicBuffer,
EGLDisplay display, EGLSyncKHR eglFence) {
// release the buffer if it hasn't already been discarded by the
// BufferQueue. This can happen, for example, when the producer of this
// buffer has reallocated the original buffer slot after this buffer
// was acquired.
status_t err = ConsumerBase::releaseBufferLocked(
buf, graphicBuffer, display, eglFence);
mEglSlots[buf].mEglFence = EGL_NO_SYNC_KHR;
return err;
}
status_t ConsumerBase::releaseBufferLocked(
int slot, const sp graphicBuffer,
EGLDisplay display, EGLSyncKHR eglFence) {
// If consumer no longer tracks this graphicBuffer (we received a new
// buffer on the same slot), the buffer producer is definitely no longer
// tracking it.
if (!stillTracking(slot, graphicBuffer)) {
return OK;
}
//release 老buffer的時候,會傳入一個mSlots[slot].mFence,即release fence
status_t err = mConsumer->releaseBuffer(slot, mSlots[slot].mFrameNumber,
display, eglFence, mSlots[slot].mFence);
if (err == BufferQueue::STALE_BUFFER_SLOT) {
freeBufferLocked(slot);
}
mSlots[slot].mFence = Fence::NO_FENCE;
return err;
}
接著surfaceflinger會去進行layer的合成,只合成HWC_FRAMEBUFFER的layer,對overlay合成的layer直接將layer的acquire fence 設置到hwcomposer中的hwc_layer_1_t結構中。
void SurfaceFlinger::doComposeSurfaces(const sp& hw, const Region& dirty)
{
/*
* and then, render the layers targeted at the framebuffer
*/
const Vector< sp >& layers(hw->getVisibleLayersSortedByZ());
const size_t count = layers.size();
const Transform& tr = hw->getTransform();
if (cur != end) {
// we're using h/w composer
for (size_t i=0 ; i& layer(layers[i]);
const Region clip(dirty.intersect(tr.transform(layer->visibleRegion)));
if (!clip.isEmpty()) {
switch (cur->getCompositionType()) {
//overlay不做處理
case HWC_OVERLAY: {
const Layer::State& state(layer->getDrawingState());
if ((cur->getHints() & HWC_HINT_CLEAR_FB)
&& i
&& layer->isOpaque() && (state.alpha == 0xFF)
&& hasGlesComposition) {
// never clear the very first layer since we're
// guaranteed the FB is already cleared
layer->clearWithOpenGL(hw, clip);
}
break;
}
//surfaceflinger對HWC_FRAMEBUFFER對應的layer用opengl合成
case HWC_FRAMEBUFFER: {
layer->draw(hw, clip);
break;
}
case HWC_FRAMEBUFFER_TARGET: {
// this should not happen as the iterator shouldn't
// let us get there.
ALOGW("HWC_FRAMEBUFFER_TARGET found in hwc list (index=%d)", i);
break;
}
}
}
layer->setAcquireFence(hw, *cur);
}
} else {
}
}
//注意參數layer為HWComposer::HWCLayerInterface,
//直接將layer的acquire fence 設置到hwcomposer中的hwc_layer_1_t結構中
void Layer::setAcquireFence(const sp& hw,
HWComposer::HWCLayerInterface& layer) {
int fenceFd = -1;
// TODO: there is a possible optimization here: we only need to set the
// acquire fence the first time a new buffer is acquired on EACH display.
// 對於overlay層,由於要去hwcomposer合成,先獲取(surface--layer對應的BufferQueue)
// 消費者中的acquire fence
if (layer.getCompositionType() == HWC_OVERLAY) {
sp fence = mSurfaceFlingerConsumer->getCurrentFence();
if (fence->isValid()) {
fenceFd = fence->dup();
if (fenceFd == -1) {
ALOGW("failed to dup layer fence, skipping sync: %d", errno);
}
}
}
//overlay層設置的fence,fencefd不為-1,如果上層是canvas繪圖,這裡也是-1,如果是opengl,
//沒准這時候生產者還沒完成繪圖呢。
//其余層都設置的fence,fencefd為-1
layer.setAcquireFenceFd(fenceFd);
}
// layer->draw —>layer->onDraw
void Layer::onDraw(const sp& hw, const Region& clip) const
{
ATRACE_CALL();
// 首先,將buffer添加到GL texture
// Bind the current buffer to the GL texture, and wait for it to be
// ready for us to draw into.
status_t err = mSurfaceFlingerConsumer->bindTextureImage();
//利用opengl合成
drawWithOpenGL(hw, clip);
}
//SurfaceFlingerConsumer::bindTextureImage—>GLConsumer::bindTextureImageLocked
status_t GLConsumer::bindTextureImageLocked() {
if (mEglDisplay == EGL_NO_DISPLAY) {
ALOGE("bindTextureImage: invalid display");
return INVALID_OPERATION;
}
GLint error;
while ((error = glGetError()) != GL_NO_ERROR) {
ST_LOGW("bindTextureImage: clearing GL error: %#04x", error);
}
glBindTexture(mTexTarget, mTexName);
if (mCurrentTexture == BufferQueue::INVALID_BUFFER_SLOT) {
if (mCurrentTextureBuf == NULL) {
ST_LOGE("bindTextureImage: no currently-bound texture");
return NO_INIT;
}
status_t err = bindUnslottedBufferLocked(mEglDisplay);
if (err != NO_ERROR) {
return err;
}
} else {
//獲取當前mCurrentTexture的mEglSlots對應的EGLImageKHR
EGLImageKHR image = mEglSlots[mCurrentTexture].mEglImage;
glEGLImageTargetTexture2DOES(mTexTarget, (GLeglImageOES)image);
while ((error = glGetError()) != GL_NO_ERROR) {
ST_LOGE("bindTextureImage: error binding external texture image %p"
": %#04x", image, error);
return UNKNOWN_ERROR;
}
}
//等待這個buffer的acquire fence觸發,也就是等待畫完
// Wait for the new buffer to be ready.
return doGLFenceWaitLocked();
}
// 等待生產者的acquire fence觸發
status_t GLConsumer::doGLFenceWaitLocked() const {
EGLDisplay dpy = eglGetCurrentDisplay();
EGLContext ctx = eglGetCurrentContext();
if (mEglDisplay != dpy || mEglDisplay == EGL_NO_DISPLAY) {
ST_LOGE("doGLFenceWait: invalid current EGLDisplay");
return INVALID_OPERATION;
}
if (mEglContext != ctx || mEglContext == EGL_NO_CONTEXT) {
ST_LOGE("doGLFenceWait: invalid current EGLContext");
return INVALID_OPERATION;
}
//等待生產者的acquire fence觸發,
if (mCurrentFence->isValid()) {
if (SyncFeatures::getInstance().useWaitSync()) {
// Create an EGLSyncKHR from the current fence.
int fenceFd = mCurrentFence->dup();
if (fenceFd == -1) {
ST_LOGE("doGLFenceWait: error dup'ing fence fd: %d", errno);
return -errno;
}
EGLint attribs[] = {
EGL_SYNC_NATIVE_FENCE_FD_ANDROID, fenceFd,
EGL_NONE
};
EGLSyncKHR sync = eglCreateSyncKHR(dpy,
EGL_SYNC_NATIVE_FENCE_ANDROID, attribs);
if (sync == EGL_NO_SYNC_KHR) {
close(fenceFd);
ST_LOGE("doGLFenceWait: error creating EGL fence: %#x",
eglGetError());
return UNKNOWN_ERROR;
}
// XXX: The spec draft is inconsistent as to whether this should
// return an EGLint or void. Ignore the return value for now, as
// it's not strictly needed.
eglWaitSyncKHR(dpy, sync, 0);
EGLint eglErr = eglGetError();
eglDestroySyncKHR(dpy, sync);
if (eglErr != EGL_SUCCESS) {
ST_LOGE("doGLFenceWait: error waiting for EGL fence: %#x",
eglErr);
return UNKNOWN_ERROR;
}
} else {
status_t err = mCurrentFence->waitForever(
"GLConsumer::doGLFenceWaitLocked");
if (err != NO_ERROR) {
ST_LOGE("doGLFenceWait: error waiting for fence: %d", err);
return err;
}
}
}
return NO_ERROR;
}
至此,surfaceflinger完成了對HWC_FRAMEBUFFER layer的合成,由於使用的是opengl,所以肯定依然得fence去協調GPU和CPU的工作。
對使用opengl合成的layer將合成結果放置到HWC_FRAMEBUFFER_TARGET layer中,然後再交給HWComposer處理。在surfaceflinger的init函數中,定義了HWC_FRAMEBUFFER_TARGET layer合成時對應的生成者和消費者,每個display對應有一個DisplayDevice作為生產者(opengl合成數據),而FramebufferSurface是對應的消費者(注意這個消費者只是處理opengl合成相關的,overlay完全由HAL層的hwcomposer處理)。
// BufferQueue
sp bq = new BufferQueue(new GraphicBufferAlloc());
//FramebufferSurface是合成的消費者,對應bq的消費端
sp<framebuffersurface> fbs = new FramebufferSurface(*mHwc, i, bq);
// DisplayDevice是合成數據的生產者,對應bq的生成端
sp hw = new DisplayDevice(this,
type, allocateHwcDisplayId(type), isSecure, token,
fbs, bq,
mEGLConfig); </framebuffersurface>
DisplayDevice::DisplayDevice(
const sp& flinger,
DisplayType type,
int32_t hwcId,
bool isSecure,
const wp& displayToken,
const sp& displaySurface,
const sp& producer,
EGLConfig config)
: mFlinger(flinger),
mType(type), mHwcDisplayId(hwcId),
mDisplayToken(displayToken),
mDisplaySurface(displaySurface),
mDisplay(EGL_NO_DISPLAY),
mSurface(EGL_NO_SURFACE),
mDisplayWidth(), mDisplayHeight(), mFormat(),
mFlags(),
mPageFlipCount(),
mIsSecure(isSecure),
mSecureLayerVisible(false),
mScreenAcquired(false),
mLayerStack(NO_LAYER_STACK),
mOrientation()
{
//利用bq創建surface
mNativeWindow = new Surface(producer, false);
ANativeWindow* const window = mNativeWindow.get();
int format;
window->query(window, NATIVE_WINDOW_FORMAT, &format);
// Make sure that composition can never be stalled by a virtual display
// consumer that isn't processing buffers fast enough. We have to do this
// in two places:
// * Here, in case the display is composed entirely by HWC.
// * In makeCurrent(), using eglSwapInterval. Some EGL drivers set the
// window's swap interval in eglMakeCurrent, so they'll override the
// interval we set here.
if (mType >= DisplayDevice::DISPLAY_VIRTUAL)
window->setSwapInterval(window, 0);
/*
* Create our display's surface
*/
// 利用EGL創建本地opengl環境,要用opengl 合成layer
EGLSurface surface;
EGLint w, h;
EGLDisplay display = eglGetDisplay(EGL_DEFAULT_DISPLAY);
surface = eglCreateWindowSurface(display, config, window, NULL);
eglQuerySurface(display, surface, EGL_WIDTH, &mDisplayWidth);
eglQuerySurface(display, surface, EGL_HEIGHT, &mDisplayHeight);
mDisplay = display;
mSurface = surface;
mFormat = format;
mPageFlipCount = 0;
mViewport.makeInvalid();
mFrame.makeInvalid();
// virtual displays are always considered enabled
mScreenAcquired = (mType >= DisplayDevice::DISPLAY_VIRTUAL);
// Name the display. The name will be replaced shortly if the display
// was created with createDisplay().
switch (mType) {
case DISPLAY_PRIMARY:
mDisplayName = "Built-in Screen";
break;
case DISPLAY_EXTERNAL:
mDisplayName = "HDMI Screen";
break;
default:
mDisplayName = "Virtual Screen"; // e.g. Overlay #n
break;
}
}
在opengl完成layer的合成後,調用SurfaceFlinger::doDisplayComposition—>hw->swapBuffers()—>DisplayDevice::swapBuffers—>eglSwapBuffers(),
void DisplayDevice::swapBuffers(HWComposer& hwc) const {
// We need to call eglSwapBuffers() if:
// (1) we don't have a hardware composer, or
// (2) we did GLES composition this frame, and either
// (a) we have framebuffer target support (not present on legacy
// devices, where HWComposer::commit() handles things); or
// (b) this is a virtual display
if (hwc.initCheck() != NO_ERROR ||
(hwc.hasGlesComposition(mHwcDisplayId) &&
(hwc.supportsFramebufferTarget() || mType >= DISPLAY_VIRTUAL))) {
//調用eglSwapBuffers去交換buffer
EGLBoolean success = eglSwapBuffers(mDisplay, mSurface);
if (!success) {
EGLint error = eglGetError();
if (error == EGL_CONTEXT_LOST ||
mType == DisplayDevice::DISPLAY_PRIMARY) {
LOG_ALWAYS_FATAL("eglSwapBuffers(%p, %p) failed with 0x%08x",
mDisplay, mSurface, error);
} else {
ALOGE("eglSwapBuffers(%p, %p) failed with 0x%08x",
mDisplay, mSurface, error);
}
}
}
}
前面的文章提到過,eglSwapBuffers會觸發DisplayDevice這個producer去dequeue buffer和queue buffer,這裡的opengl合成和上層的opengl繪圖類似,在queuebuffer中就會為該buffer設置一個acquire buffer,傳遞給消費者FramebufferSurface,queue buffer會觸發FramebufferSurface::onFrameAvailable(),
void FramebufferSurface::onFrameAvailable() {
sp buf;
sp acquireFence;
// acquire buffer,由於surfaceflinger是用opengl合成HWC_FRAMEBUFFER_TARGET layer的,
// 所以有可能“合成”這個生產還未完成,獲取queue buffer時設置的fence
status_t err = nextBuffer(buf, acquireFence);
if (err != NO_ERROR) {
ALOGE("error latching nnext FramebufferSurface buffer: %s (%d)",
strerror(-err), err);
return;
}
err = mHwc.fbPost(mDisplayType, acquireFence, buf);
if (err != NO_ERROR) {
ALOGE("error posting framebuffer: %d", err);
}
}
status_t FramebufferSurface::nextBuffer(sp& outBuffer, sp& outFence) {
Mutex::Autolock lock(mMutex);
BufferQueue::BufferItem item;
//首先acquire buffer
status_t err = acquireBufferLocked(&item, 0);
//把老的buffer先release掉,還給BufferQueue,release時肯定得添加個release fence
// If the BufferQueue has freed and reallocated a buffer in mCurrentSlot
// then we may have acquired the slot we already own. If we had released
// our current buffer before we call acquireBuffer then that release call
// would have returned STALE_BUFFER_SLOT, and we would have called
// freeBufferLocked on that slot. Because the buffer slot has already
// been overwritten with the new buffer all we have to do is skip the
// releaseBuffer call and we should be in the same state we'd be in if we
// had released the old buffer first.
if (mCurrentBufferSlot != BufferQueue::INVALID_BUFFER_SLOT &&
item.mBuf != mCurrentBufferSlot) {
// Release the previous buffer.
err = releaseBufferLocked(mCurrentBufferSlot, mCurrentBuffer,
EGL_NO_DISPLAY, EGL_NO_SYNC_KHR);
if (err < NO_ERROR) {
ALOGE("error releasing buffer: %s (%d)", strerror(-err), err);
return err;
}
}
mCurrentBufferSlot = item.mBuf;
mCurrentBuffer = mSlots[mCurrentBufferSlot].mGraphicBuffer;
outFence = item.mFence;
outBuffer = mCurrentBuffer;
return NO_ERROR;
}
status_t ConsumerBase::releaseBufferLocked(
int slot, const sp graphicBuffer,
EGLDisplay display, EGLSyncKHR eglFence) {
// If consumer no longer tracks this graphicBuffer (we received a new
// buffer on the same slot), the buffer producer is definitely no longer
// tracking it.
if (!stillTracking(slot, graphicBuffer)) {
return OK;
}
CB_LOGV("releaseBufferLocked: slot=%d/%llu",
slot, mSlots[slot].mFrameNumber);
//mSlots[slot].mFence這個release fence傳回給BufferQueue
//這個release fence是在哪裡設置的呢?應該是hwcomposer底層設置的,然後通過
//postFramebuffer()——>hw->onSwapBuffersCompleted()將release fence
//設置到對應的slot中,
status_t err = mConsumer->releaseBuffer(slot, mSlots[slot].mFrameNumber,
display, eglFence, mSlots[slot].mFence);
if (err == BufferQueue::STALE_BUFFER_SLOT) {
freeBufferLocked(slot);
}
mSlots[slot].mFence = Fence::NO_FENCE;
return err;
}
void SurfaceFlinger::postFramebuffer()
{
ATRACE_CALL();
const nsecs_t now = systemTime();
mDebugInSwapBuffers = now;
HWComposer& hwc(getHwComposer());
if (hwc.initCheck() == NO_ERROR) {
hwc.commit();
}
// make the default display current because the VirtualDisplayDevice code cannot
// deal with dequeueBuffer() being called outside of the composition loop; however
// the code below can call glFlush() which is allowed (and does in some case) call
// dequeueBuffer().
getDefaultDisplayDevice()->makeCurrent(mEGLDisplay, mEGLContext);
for (size_t dpy=0 ; dpy hw(mDisplays[dpy]);
const Vector< sp >& currentLayers(hw->getVisibleLayersSortedByZ());
//看名字就是完成了framebuffertarget layer的swapbuffers,
hw->onSwapBuffersCompleted(hwc);
const size_t count = currentLayers.size();
int32_t id = hw->getHwcDisplayId();
if (id >=0 && hwc.initCheck() == NO_ERROR) {
HWComposer::LayerListIterator cur = hwc.begin(id);
const HWComposer::LayerListIterator end = hwc.end(id);
for (size_t i = 0; cur != end && i < count; ++i, ++cur) {
currentLayers[i]->onLayerDisplayed(hw, &*cur);
}
} else {
for (size_t i = 0; i < count; i++) {
currentLayers[i]->onLayerDisplayed(hw, NULL);
}
}
}
}
void DisplayDevice::onSwapBuffersCompleted(HWComposer& hwc) const {
if (hwc.initCheck() == NO_ERROR) {
mDisplaySurface->onFrameCommitted();
}
}
// onFrameCommitted主要就是獲取hwcomposer設置的release fence,然後設置到slot中
void FramebufferSurface::onFrameCommitted() {
sp fence = mHwc.getAndResetReleaseFence(mDisplayType);
if (fence->isValid() &&
mCurrentBufferSlot != BufferQueue::INVALID_BUFFER_SLOT) {
status_t err = addReleaseFence(mCurrentBufferSlot,
mCurrentBuffer, fence);
ALOGE_IF(err, "setReleaseFenceFd: failed to add the fence: %s (%d)",
strerror(-err), err);
}
}
sp HWComposer::getAndResetReleaseFence(int32_t id) {
if (uint32_t(id)>31 || !mAllocatedDisplayIDs.hasBit(id))
return Fence::NO_FENCE;
int fd = INVALID_OPERATION;
if (mHwc && hwcHasApiVersion(mHwc, HWC_DEVICE_API_VERSION_1_1)) {
const DisplayData& disp(mDisplayData[id]);
// 這裡的disp.framebufferTarget->releaseFenceFd應該就是底層hwcomposer設置的
if (disp.framebufferTarget) {
fd = disp.framebufferTarget->releaseFenceFd;
disp.framebufferTarget->acquireFenceFd = -1;
disp.framebufferTarget->releaseFenceFd = -1;
}
}
return fd >= 0 ? new Fence(fd) : Fence::NO_FENCE;
}
acquire buffer後,調用HWComposer的fbPost函數,設置framebufferTarget的buffer handle以及framebufferTarget layer對應的acquireFenceFd。
int HWComposer::fbPost(int32_t id,
const sp& acquireFence, const sp& buffer) {
if (mHwc && hwcHasApiVersion(mHwc, HWC_DEVICE_API_VERSION_1_1)) {
//4.4走這個分支
return setFramebufferTarget(id, acquireFence, buffer);
} else {
acquireFence->waitForever("HWComposer::fbPost");
return mFbDev->post(mFbDev, buffer->handle);
}
}
// 設置display對應的framebufferTarget->handle和framebufferTarget->acquireFenceFd
status_t HWComposer::setFramebufferTarget(int32_t id,
const sp& acquireFence, const sp& buf) {
if (uint32_t(id)>31 || !mAllocatedDisplayIDs.hasBit(id)) {
return BAD_INDEX;
}
DisplayData& disp(mDisplayData[id]);
if (!disp.framebufferTarget) {
// this should never happen, but apparently eglCreateWindowSurface()
// triggers a Surface::queueBuffer() on some
// devices (!?) -- log and ignore.
ALOGE("HWComposer: framebufferTarget is null");
return NO_ERROR;
}
// 如果acquireFence fencefd不等於-1,也就是說opengl使用了硬件實現去合成layer
int acquireFenceFd = -1;
if (acquireFence->isValid()) {
acquireFenceFd = acquireFence->dup();
}
//設置framebufferTarget的buffer handle以及framebufferTarget layer對應的acquireFenceFd
// ALOGD("fbPost: handle=%p, fence=%d", buf->handle, acquireFenceFd);
disp.fbTargetHandle = buf->handle;
disp.framebufferTarget->handle = disp.fbTargetHandle;
disp.framebufferTarget->acquireFenceFd = acquireFenceFd;
return NO_ERROR;
}
而對overlay對應的layer而言,前面只設置了acquire fence,在hwcomposer HAL處理後肯定會給添加一個release fence,而這一部分代碼我們看不到實現。那麼這個release fence是如何設置到layer中的?
void SurfaceFlinger::postFramebuffer()
{
for (size_t dpy=0 ; dpy hw(mDisplays[dpy]);
const Vector< sp >& currentLayers(hw->getVisibleLayersSortedByZ());
hw->onSwapBuffersCompleted(hwc);
const size_t count = currentLayers.size();
int32_t id = hw->getHwcDisplayId();
if (id >=0 && hwc.initCheck() == NO_ERROR) {
HWComposer::LayerListIterator cur = hwc.begin(id);
const HWComposer::LayerListIterator end = hwc.end(id);
//對所有的layer執行onLayerDisplayed,設置release fence,
//當hwcomposer將layer合成完成後,這個release fence就會觸發。
for (size_t i = 0; cur != end && i < count; ++i, ++cur) {
currentLayers[i]->onLayerDisplayed(hw, &*cur);
}
} else {
for (size_t i = 0; i < count; i++) {
currentLayers[i]->onLayerDisplayed(hw, NULL);
}
}
}
}
void Layer::onLayerDisplayed(const sp& hw,
HWComposer::HWCLayerInterface* layer) {
if (layer) {
layer->onDisplayed();
//將fence設置到slot中
mSurfaceFlingerConsumer->setReleaseFence(layer->getAndResetReleaseFence());
}
}
virtual sp getAndResetReleaseFence() {
//獲取layer的releaseFenceFd
int fd = getLayer()->releaseFenceFd;
getLayer()->releaseFenceFd = -1;
//new 一個fence
return fd >= 0 ? new Fence(fd) : Fence::NO_FENCE;
}
 Android 繪圖機制:canvas初解
Android 繪圖機制:canvas初解
Canvas 即“畫布”的意思,在Android中用其來進行2D繪畫。在使用canvas來進行繪圖時,一般都會自定義一個View來重寫
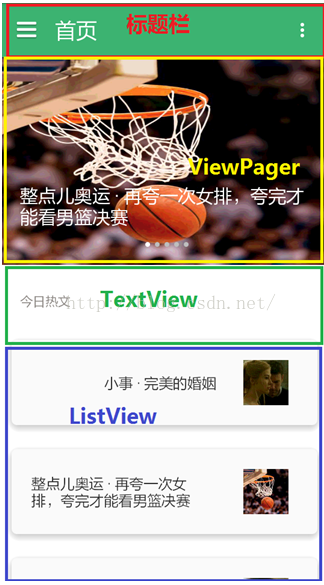 仿知乎日報第六篇:為MainFragement加載數據
仿知乎日報第六篇:為MainFragement加載數據
一.前面講了,MainFragment的布局就是一個ViewPager,而ViewPager的一個個頁面就是首頁,日常心理學,用戶推薦日報,電影日報,不許無聊,設計日報,
 Android微信自動搶紅包插件優化和實現
Android微信自動搶紅包插件優化和實現
又是興趣系列 網上有很多自動強紅包的例子和代碼,筆者也是做了一些優化。 先說說自己的兩個個優勢 1.可以在聊天界面自動強不依賴於通知欄推送 2.可以在屏幕熄滅的時候的時候
 android輕松管理安卓應用中的log日志 發布應用時log日志全部去掉的方法
android輕松管理安卓應用中的log日志 發布應用時log日志全部去掉的方法
管理log一般有兩種方法,博主推薦大家使用下面的第一種方法:第一種方法:第一步:定義一個logTools工具類,相信你能夠看懂的,誰的log,可以用誰的名字做方法名,如l