編輯:關於Android編程
伴隨著“Dalvik is dead,long live Dalvik“這行AOSP代碼提交日志,在Android5.0中,ART運行時取代了Dalvik虛擬機。雖然Dalvik虛擬機不再使用,但是它曾經的作用是不可磨滅的。因此,在研究ART運行時的垃圾收集機制之前,先理解Dalvik虛擬機的垃圾收集機制也是很重要和有幫助的。因此,本文就對Dalvik虛擬機的垃圾收集機進行簡要介紹和制定學習計劃。
之所以說理解Dalvik虛擬機的垃圾收集機制對學習ART運行時的垃圾收集機制有幫助,是因為兩者都使用到了一些共同或者相通的技術,並且前者的實現相對簡單一些。這樣我們就可以從簡單的學起。等到有了一定的基礎之後,再學習復雜的就會容易理解很多。
好了,廢話不多說,我們開始介紹Dalvik虛擬機的垃圾收集機制涉及到的基本概念或者說術語,如圖1所示:
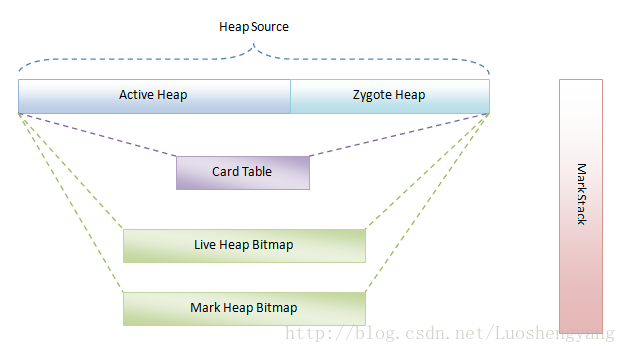
圖1 Dalvik虛擬機垃圾收集機制的基本概念
Dalvik虛擬機用來分配對象的堆劃分為兩部分,一部分叫做Active Heap,另一部分叫做Zygote Heap。我們可以知道,應用程序進程是由Zygote進程fork出來的。也就是說,應用程序進程使用了一種寫時拷貝技術(COW)來復制了Zygote進程的地址空間。這意味著一開始的時候,應用程序進程和Zygote進程共享了同一個用來分配對象的堆。然而,當Zygote進程或者應用程序進程對該堆進行寫操作時,內核就會執行真正的拷貝操作,使得Zygote進程和應用程序進程分別擁有自己的一份拷貝。
拷貝是一件費時費力的事情。因此,為了盡量地避免拷貝,Dalvik虛擬機將自己的堆劃分為兩部分。事實上,Dalvik虛擬機的堆最初是只有一個的。也就是Zygote進程在啟動過程中創建Dalvik虛擬機的時候,只有一個堆。但是當Zygote進程在fork第一個應用程序進程之前,會將已經使用了的那部分堆內存劃分為一部分,還沒有使用的堆內存劃分為另外一部分。前者就稱為Zygote堆,後者就稱為Active堆。以後無論是Zygote進程,還是應用程序進程,當它們需要分配對象的時候,都在Active堆上進行。這樣就可以使得Zygote堆盡可能少地被執行寫操作,因而就可以減少執行寫時拷貝的操作。在Zygote堆裡面分配的對象其實主要就是Zygote進程在啟動過程中預加載的類、資源和對象了。這意味著這些預加載的類、資源和對象可以在Zygote進程和應用程序進程中做到長期共享。這樣既能減少拷貝操作,還能減少對內存的需求。
明白了Dalvik虛擬機為什麼要把用來分配對象的堆劃分為Active堆和Zygote堆之後,我們再看到底堆是個什麼東西,請看圖2:
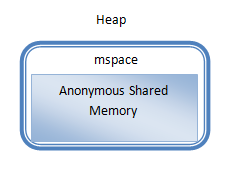
圖2 Dalvik虛擬機的堆
在Dalvik虛擬機中,堆實際上就是一塊匿名共享內存。Dalvik虛擬機並不是直接管理這塊匿名共享內存,而是將它封裝成一個mspace,交給C庫來管理。mspace是libc中的概念,我們可以通過libc提供的函數create_mspace_with_base創建一個mspace,然後再通過mspace_開頭的函數管理該mspace。例如,我們可以通過mspace_malloc和mspace_bulk_free來在指定的mspace中分配和釋放內存。實際上,我們在使用libc提供的函數malloc和free分配和釋放內存時,也是在一個mspace進行的,只不過這個mspace是由libc默認創建的。
Dalvik虛擬機除了要給應用層分配對象之外,最重要的還是要對這些已經分配出去的對象進行管理,也就是要在對象不再被使用的時候,對其進行自動回收。沒吃過豬肉,也見過豬跑,自動回收對象(也就是垃圾收集)的算法不用多說,就是耳熟能詳的Mark-Sweep算法。
顧名思義,Mark-Sweep垃圾收集算法主要分為兩個階段:Mark和Sweep。Mark階段從對象的根集開始標記被引用的對象。標記完成後,就進入到Sweep階段,而Sweep階段所做的事情就是回收沒有被標記的對象占用的內存。這裡涉及到的一個核心概念就是我們怎麼標記對象有沒有被引用的,換句說就是通過什麼數據結構來描述對象有沒有被引用。是的,就是圖1中的Heap Bitmap了。Heap Bitmap的結構如圖3所示:
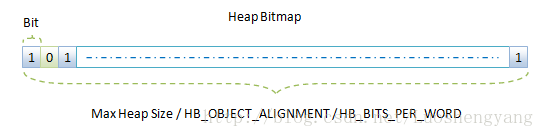
圖3 Heap Bitmap
從名字就可以推斷出,Heap Bitmap使用位圖來標記對象是否被使用。如果一個對象被引用,那麼在Bitmap中與它對應的那一位就會被設置為1。否則的話,就設置為0。在Dalvik虛擬機中,使用一個unsigned long數組來描述一個Heap Bitmap。我們假設堆的大小為Max Heap Size。我們使用libc提供的函數mspace_malloc來從堆裡面分配內存時,得到的內存的地址總是對齊到HB_OBJECT_ALIGNMENT的。HB_OBJECT_ALIGNMENT的值等於8,也就是說,我們分配的對象的地址的最低三位總是0。這意味著我們在考慮Bitmap中的位與對象的對應關系時,可以不考慮這最低三位的值。這樣可以大大地減少Bitmap的大小。例如,在32位設備上,每一個對象的地址都有32位,除去最低的三位,我們在考慮Bitmap與對象的對應關系時,只需要考慮高29位就可以了。因此,在計算所需要的Bitmap的大小時,就可以將堆的大小值除以HB_OBJECT_ALIGNMENT,即除以8。
假設一個unsigned long數占HB_BITS_PER_WORD個位,那麼,我們就需要一個大小為(Max Heap Size / HB_OBJECT_ALIGNMENT /HB_BITS_PER_WORD)的unsigned long數組來描述一個大小為Max Heap Size的堆。在32位設備上,一個unsigned long數占用32位,即HB_BITS_PER_WORD的值等於32。綜合上面的描述,我們就可以知道,一個大小為Max Heap Size的堆需要一個大小為(Max Heap Size / 8 / 32)的unsigned long數組來描述,即需要一塊字節數等於(Max Heap Size / 8 / 32)× 4的內存來描述。
在圖1中,我們使用了兩個Bitmap來描述堆的對象,一個稱為Live Bitmap,另一個稱為Mark Bitmap。Live Bitmap用來標記上一次GC時被引用的對象,也就是沒有被回收的對象,而Mark Bitmap用來標記當前GC有被引用的對象。有了這兩個信息之後,我們就可以很容易地知道哪些對象是需要被回收的,即在Live Bitmap在標記為1,但是在Mark Bitmap中標記為0的對象。
在垃圾收集的Mark階段,要求除了垃圾收集線程之外,其它的線程都停止,否則的話,就會可能導致不能正確地標記每一個對象。這種現象在垃圾收集算法中稱為Stop The World,會導致程序中止執行,造成停頓的現象。為了盡可能地減少停頓,我們必須要允許在Mark階段有條件地允許程序的其它線程執行。這種垃圾收集算法稱為並行垃圾收集算法(Concurrent GC)。
為了實現Concurrent GC,Mark階段又劃分兩個子階段。第一個子階段只負責標記根集對象。所謂的根集對象,就是指在GC開始的瞬間,被全局變量、棧變量和寄存器等引用的對象。有了這些根集變量之後,我們就可以順著它們找到其余的被引用變量。例如,一個棧變量引了一個對象,而這個對象又通過成員變量引用了另外一個對象,那該被引用的對象也會同時標記為正在使用。這個標記被根集對象引用的對象的過程就是第二個子階段。在Concurrent GC,第一個子階段是不允許垃圾收集線程之外的線程運行的,但是第二個子階段是允許的。不過,在第二個子階段執行的過程中,如果一個線程修改了一個對象,那麼該對象必須要記錄起來,因為它很有可能引用了新的對象,或者引用了之前未引用過的對象。如果不這樣做的話,那麼就會導致被引用對象還在使用然而卻被回收。這種情況出現在只進行部分垃圾收集的情況,這時候Card Table的作用就是用來記錄非垃圾收集堆對象對垃圾收集堆對象的引用。Dalvik虛擬機進行部分垃圾收集時,實際上就是只收集在Active堆上分配的對象。因此對Dalvik虛擬機來說,Card Table就是用來記錄在Zygote堆上分配的對象在部收垃圾收集執行過程中對在Active堆上分配的對象的引用。
我們是不是想到再用一個Bitmap在描述上述第二個子階段被修改的對象呢?雖然我們盡大努力減少了用來標記對象的Bitmap的大小,不過還是比較可觀的。因此,為了減少內存的消耗,我們使用另外一種技術來標記Mark第二子階段被修改的對象。這種技術使用到了一種稱為Card Table的數據結構,如圖4所示:
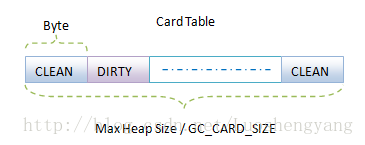
圖4 Card Table
從名字可以看出,Card Table由Card組成,一個Card實際上就是一個字節,它的值要麼是CLEAN,要麼是DIRTY。如果一個Card的值是CLEAN,就表示與它對應的對象在Mark第二子階段沒有被程序修改過。否則的話,就意味著被程序修改過,對於這些被修改過的對象。需要在Mark第二子階段結束之後,再次禁止垃圾收集線程之外的其它線程執行,以便垃圾收集線程再次根據Card Table記錄的信息對被修改過的對象引用的其它對象進行重新標記。由於Mark第二子階段執行的時間不會太長,因此在該階段被修改的對象不會很多,這樣就可以保證第二次子階段結束後,再次執行標記對象的過程是很快的,因而此時對程序造成的停頓非常小。
在Card Table中,在連續GC_CARD_SIZE地址中的對象共用一個Card。Dalvik虛擬機將GC_CARD_SIZE的值設置為128。因此,假設堆的大小為Max Heap Size,那麼我們只需要一塊字節數為(Max Heap Size / 128)的Card Table。相比大小為(Max Heap Size / 8 / 32)× 4的Bitmap,減少了一半的內存需求。
在Mark階段,Dalvik虛擬機能過遞歸方式來標記對象。但是,這不是通過函數的遞歸調用來實現的,而是借助一個稱為Mark Stack的棧來實現的。具體來說,當我們標記完成根集對象之後,就按照它們的地址從小到大的順序標記它們所引用的其它對象。假設有A、B、C和D四個對象,它的地址大小關系為A < B < C < D,其中,B和D是根集對象,A被D引用,C沒有被B和D引用。那麼我們將依次遍歷B和D。當遍歷到B的時候,沒有發現它引用其它對象,然後就繼續向前遍歷D對象。發現它引用了A對象。按照遞歸的算法,這時候除了標記A對象是正在使用之外,還應該去檢查A對象有沒有引用其它對象,然後又再檢查它引用的對象有沒有又引用其它的對象,一直這樣遍歷下去。這樣就跟函數遞歸一樣。更好的做法是將對象A記錄在一個Mark Stack中,然後繼續檢查地址值比對象D大的其它對象。對於地址值比對象D大的其它對象,如果它們引用了一個地址值比它們小的其它對象,那麼這些其它對象同樣要記錄在Mark Stack中。等到該輪檢查結束之後,再回過頭來檢查記錄在Mark Stack裡面的對象。然後又重復上述過程,直到Mark Stack等於空為止。
這就是我們在圖1中顯示的Mark Stack的作用,它的具體結構如圖5所示:
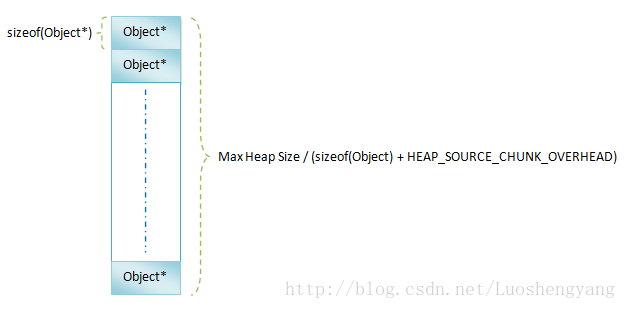
圖5 Mark Stack
在Dalvik虛擬機中,每一個對象都是從Object類繼承下來的,也就是說,每一個對象占用的內存大小都至少等於sizeof(Object)。此外,我們通過libc提供的函數mspace_malloc為對象分配內存時,libc需要額外的內存來記錄被分配出去的內存的信息。例如,需要記錄被分配出去的內存的大小。每一塊分配出去的內存需要額外的HEAP_SOURCE_CHUNK_OVERHEAD內存來記錄上述的管理信息。因此,在Dalvik虛擬機中,每一個對象的大小都至少為sizeof(Object) + HEAP_SOURCE_CHUNK_OVERHEAD。這就意味著對於一個大小為Max Heap Size的堆來說,最多可以分配Max Heap Size / (sizeof(Object) + HEAP_SOURCE_CHUNK_OVERHEAD)個對象。於是,在最壞情況下,我們就需要一個大小為(Max Heap Size / (sizeof(Object) + HEAP_SOURCE_CHUNK_OVERHEAD))的Object*數組來描述Mark Stack,以便可以實現上述的非遞歸函數調用的遞歸標記算法。
至此,我們就對Dalvik虛擬機的垃圾收集機制中涉及到的基礎概念分析完成了。沒有結合代碼來分析,可能這些概念一時還難以理解通透。不過不要緊,接下來我們將按照以下三個情景來結合源碼深入分析上述的概念:
按照這三個情景學習Davlik虛擬機的垃圾收集機制之後,我們就會對上面涉及的概念有一個清晰的認識了,同時也會我們後面學習ART運行時的垃圾收集機集打下堅實的基礎。
 Android自定義Chronometer實現短信驗證碼秒表倒計時功能
Android自定義Chronometer實現短信驗證碼秒表倒計時功能
本文實例為大家分享了Chronometer實現倒計時功能,Android提供了實現按照秒計時的API,供大家參考,具體內容如下一、自定義ChronometerView 繼
 Android教程-從零開始一步一步接入SDK
Android教程-從零開始一步一步接入SDK
從零開始一步一步接入SDK 本篇博客想總結一下筆者在接入手游渠道SDK的一些經驗方法,為想接入手游渠道或者想學習如何接入SDK的童鞋們提供一個參考。本篇博客基於Andr
 Android開發筆記(一百零八)智能語音
Android開發筆記(一百零八)智能語音
智能語音技術如今越來越多的app用到了語音播報功能,例如地圖導航、天氣預報、文字閱讀、口語訓練等等。語音技術主要分兩塊,一塊是語音轉文字,即語音識別;另一塊是文字轉語音,
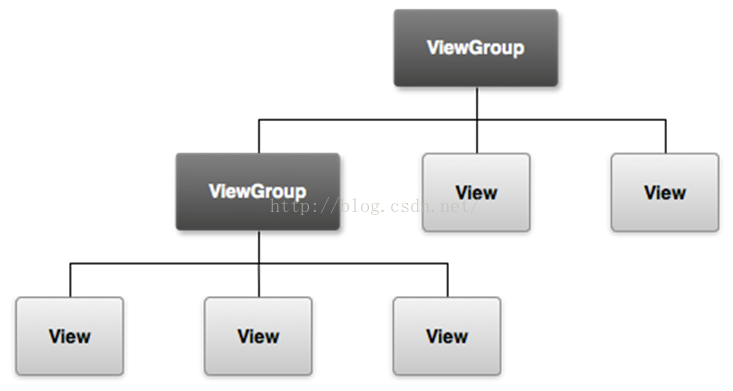 Android UI概述和常用控件
Android UI概述和常用控件
一、UI 概述Android應用程序的用戶界面是一切,用戶可以看到並與之交互。UI 是用戶能看見並可交互的組件。– 系統 UI– 自定義 UI&n