編輯:Android資訊
這一篇來分析一下HashMap的源碼,為了在後面講解Android緩存機制做准備,因為我們知道在Android的緩存機制中無論是用第三方的還是我們自己寫的,一般都會用到LruCache或者LinkedHashMap類,而LruCache裡面封裝的又是LinkedHashMap,LinkedHashMap又是HashMap的子類,所以這一篇我們有必要把HashMap的源碼分析一下,然後最終再來講解一下Android的緩存機制。HashMap的構造方法比較多,我們就隨便挑兩個最常用的來分析,其實其他的也都差不多,我們看一下
public HashMap() {
table = (HashMapEntry<K, V>[]) EMPTY_TABLE;
threshold = -1; // Forces first put invocation to replace EMPTY_TABLE
}
在HashMap中有一個table,保存的是一個HashMapEntry類型的數組,也是後面我們要講的專門存儲數據用的,而EMPTY_TABLE其實就是一個程度為2的HashMapEntry類型的數組,來看一下
private static final int MINIMUM_CAPACITY = 4;
…………………
private static final Entry[] EMPTY_TABLE
= new HashMapEntry[MINIMUM_CAPACITY >>> 1];
MINIMUM_CAPACITY往右移動一位,大小變為2了,我們再來看一下HashMapEntry這個類
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override public final boolean equals(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
return Objects.equal(e.getKey(), key)
&& Objects.equal(e.getValue(), value);
}
@Override public final int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
@Override public final String toString() {
return key + "=" + value;
}
}
我們看到他有4個變量,其中的key和value就是我們常見的兩個,而另外的兩個是存儲HashMapEntry的時候用的,其中他還有幾個的方法,因為我們知道HashMap是一個數組加鏈表的形式存儲的,hashCode是用來判斷存儲在哪個數組裡面的,equals判斷是否是同一個對象,HashMap存儲的其實就是HashMapEntry。
我們再看HashMap的另外一個構造方法
private static final int MINIMUM_CAPACITY = 4;
/**
* Max capacity for a HashMap. Must be a power of two >= MINIMUM_CAPACITY.
*/
private static final int MAXIMUM_CAPACITY = 1 << 30;
………………………
public HashMap(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("Capacity: " + capacity);
}
if (capacity == 0) {
@SuppressWarnings("unchecked")
HashMapEntry<K, V>[] tab = (HashMapEntry<K, V>[]) EMPTY_TABLE;
table = tab;
threshold = -1; // Forces first put() to replace EMPTY_TABLE
return;
}
if (capacity < MINIMUM_CAPACITY) {
capacity = MINIMUM_CAPACITY;
} else if (capacity > MAXIMUM_CAPACITY) {
capacity = MAXIMUM_CAPACITY;
} else {
capacity = Collections.roundUpToPowerOfTwo(capacity);
}
makeTable(capacity);
}
上面的比較簡單,我們先來看第26行,調用的是Collections的一個方法,其實他表示的就是找到一個比capacity大的2的n次方的最小值,可能不是太明白,我舉個例子,如果capacity是3就返回4,因為2的1次方比3小,不合適,所以是2的2次方,同樣如果capacity是9則返回16,因為2的3次方是8比9小,所以返回2的4次方16,這樣說大家可能比較明白。我們順便來看一下他的源碼
/**
* Returns the smallest power of two >= its argument, with several caveats:
* If the argument is negative but not Integer.MIN_VALUE, the method returns
* zero. If the argument is > 2^30 or equal to Integer.MIN_VALUE, the method
* returns Integer.MIN_VALUE. If the argument is zero, the method returns
* zero.
* @hide
*/
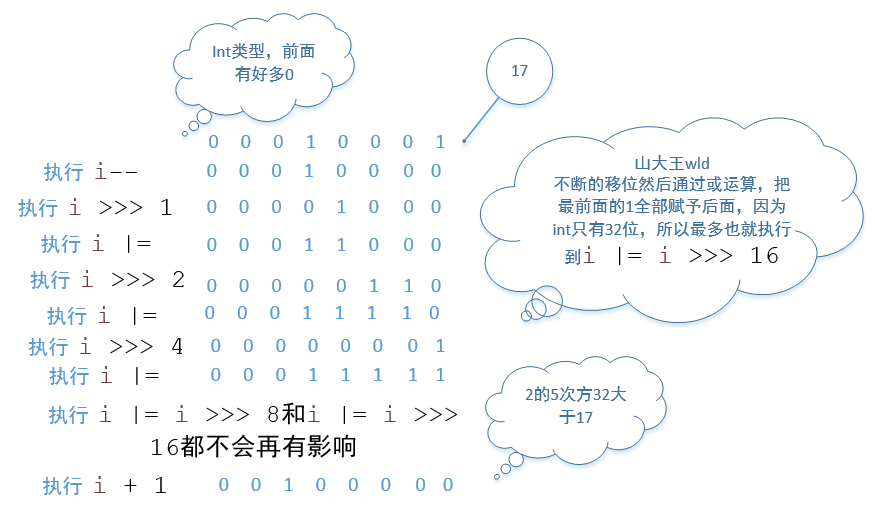
public static int roundUpToPowerOfTwo(int i) {
i--; // If input is a power of two, shift its high-order bit right.
// "Smear" the high-order bit all the way to the right.
i |= i >>> 1;
i |= i >>> 2;
i |= i >>> 4;
i |= i >>> 8;
i |= i >>> 16;
return i + 1;
}
其實上面代碼很好理解,就是高位(這裡我們只研究正整數,這個高位不是二進制的最高位,這裡是指把它轉化為二進制之後從左往右數第一次出現1的那個位置)的1往後移位然後通過或運算把後面的所有位都置1,然後最後在加上1就相當於高位之後(包括高位)全部為0,而高位的前一位進位為1,就是2的n次方了,並且這個2的n次方正好是比我們要計算的這個數大的最小的2的n次方,可能大家會有疑問,第10行為什麼還要執行i–,因為如果不執行i–,當我們傳入的正好是2的n次方的時候,結果返回的是2的n+1次方,這不是我們想要的結果,我來給大家畫個圖可能大家就明白了
然後我們再看上面的makeTable方法,我們來看一下源碼
/**
* Allocate a table of the given capacity and set the threshold accordingly.
* @param newCapacity must be a power of two
*/
private HashMapEntry<K, V>[] makeTable(int newCapacity) {
@SuppressWarnings("unchecked") HashMapEntry<K, V>[] newTable
= (HashMapEntry<K, V>[]) new HashMapEntry[newCapacity];
table = newTable;
threshold = (newCapacity >> 1) + (newCapacity >> 2); // 3/4 capacity
return newTable;
}
我們看到其實就是初始化table,這個table是一個HashMapEntry類型的數組,就是存放HashMapEntry的,然後我們還看到threshold這樣的一個值,其實他就是數組存放的阈值,他不像ArrayList等數組滿了之後再擴容,HashMap是判斷當前的HashMapEntry對象如果超過threshold就會擴容,他擴容的最終大小必須是2的n次方,這一點要牢記,待會會講到,我們看到threshold值大概是newCapacity的3/4也就是數組長度的75%。
到現在為止HashMap的初始化我們已經基本上講完了,我們看到HashMap源碼中的方法也比較多,我們就撿我們常用的的幾個來分析,我們先看一下put方法
@Override public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}
HashMap中是允許key為null的,我們看上面的2-4行,如果key為null就會調用putValueForNullKey這個方法,我們看一下他的源碼
private V putValueForNullKey(V value) {
HashMapEntry<K, V> entry = entryForNullKey;
if (entry == null) {
addNewEntryForNullKey(value);
size++;
modCount++;
return null;
} else {
preModify(entry);
V oldValue = entry.value;
entry.value = value;
return oldValue;
}
}
我們看到entryForNullKey其實就是個HashMapEntry
transient HashMapEntry<K, V> entryForNullKey;
我們再來看一下如果entry == null,說明HashMap中沒有key為null的HashMapEntry,那麼就造一個,然後size和modCount都要加一,size是 HashMap的大小,modCount是指修改的次數,主要在循環輸出的時候用來判斷HashMap是否有改動,如果有改動就會報ConcurrentModificationException異常,我們來看一下addNewEntryForNullKey的源碼
void addNewEntryForNullKey(V value) {
entryForNullKey = new HashMapEntry<K, V>(null, value, 0, null);
}
我們發現代碼量很少,就一行,初始化了一個HashMapEntry對象,然後把value存進去,其他的都為null或0,這就是一個key為null的HashMapEntry,在上面我們看到如果存在key為null的HashMapEntry就會把entryForNullKey的value修改,然後返回原來的value,這之前又調用了preModify方法,其實他是個空方法,什麼都沒做,但他會在他的子類LinkedHashMap中調用,key為null的我們分析完了。
下面我們再來分析key不為null的情況,我們還看上面的put方法,在第6行計算出hash值,第8行根據計算的hash值算出存儲的位置,其實第8行很有講究,設計的非常巧妙,我們在前面說過HashMap初始化大小的時候都是2的n次方,原因就在這,因為2的n次方換成二進制就是前面有個1後面全是0,如果減去1就變成之前為1的位和他前面的都是0,而他後面的全是1,舉個簡單例子,2的3次方是8,換成二進制就是前面有個1後面有3個0,一共4位,如果減去1就變成後面3位都是1,前面的都為0,如果在與hash值與運算,那麼算得結果永遠都是0到2的n次方減1之間,永遠都不會出現數組越界。我們看到上面put方法中的第8行,通過與運算獲得存放數組的下標index,然後在10到15行,通過查找他所在的那個數組有沒有存放過key值相同的,如果有就把他替換,然後返回原來的value,比較的時候首先是通過hash值,如果hash值相同則調用equals方法,這裡要說一下,如果hash值不同,則entry肯定不同,如果hash相同,則entry可能相同也可能不同,需要調用equals進行比較,相反如果equals相同則hash值肯定相同,如果equals不相同則hash值有可能相同也有可能不相同。我們再來看一下put的20到23行,如果放進去之後大小大於阈值則會擴容,這個阈值threshold我們剛才在上面講過,大概是數組長度的75%,擴容調用了doubleCapacity方法,因為擴容之後老數據還要重新排放,這個源碼我們最後在分析,擴容之後然後調用addNewEntry方法,把它存進去,我們來看一下他的源碼
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}
代碼很簡單,就一行,我們看到前面有個table[index],後面也有一個,大家不要暈,代碼是先要執行後面的,執行完之後然後在賦值給前面的,我們上面講過HashMapEntry構造函數的最後一個參數就是他的next,也是HashMapEntry類型的,如果原來沒有就為空,就把當前new的HashMapEntry放到數組中,如果有就把他掛到當前new的HashMapEntry後面,然後再把new的這個HashMapEntry放到數組中,因為HashMap是數組加鏈表的形式存放的,我給大家畫一個圖便於理解。
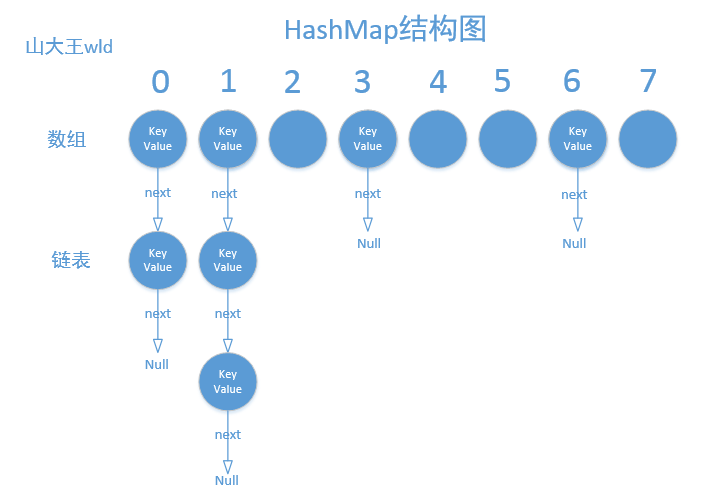
首先是根據Hash值找到所在數組的下標,因為不同的Hash值通過數組長度的與運算可能會有相同的結果,如果原來數組中沒有就把它存進去,如果原來數組有了就判斷他的key值是否相同,如果相同就把他替換,如果不相同就把原來數組這個位置的掛載到當前的下面,然後把當前的放到數組中的這個位置。
下面我們在看它的另一個方法get
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}
上面代碼也很簡單,首先如果key為null則第2-5行是取出key為null的value,我們主要來看9-15行,第9行通過計算的hash值找到所在的數組的下標,然後取出HashMapEntry,如果不為空就比較key值是否相同,如果相同就返回,不相同就找它的next下一個,就像上面HashMap結構圖中的那樣,首先要找到所在的位置,然後從上往下比較,找到則返回value,否則返回null。
我們再來看一下HashMap的還一個方法containsKey和上面的get差不多,只不過他是個判斷,但並不會返回value的值,我們簡單看一下
@Override public boolean containsKey(Object key) {
if (key == null) {
return entryForNullKey != null;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return true;
}
}
return false;
}
還有一個判斷是否包含指定的value的方法public boolean containsValue(Object value),這個其實和上面差不多,我們就不在拿出來分析,我們再看capacityForInitSize這個方法
static int capacityForInitSize(int size) {
int result = (size >> 1) + size; // Multiply by 3/2 to allow for growth
// boolean expr is equivalent to result >= 0 && result<MAXIMUM_CAPACITY
return (result & ~(MAXIMUM_CAPACITY-1))==0 ? result : MAXIMUM_CAPACITY;
}
這個方法是擴容用的,根據傳入的map的大小進行擴容,擴容的大小是傳入size的1.5倍,最後一行是根據擴容的大小判斷返回值,如果把它全部換成二進制形式就很明白了,就是如果擴容的大小大於1<<30則返回1<<30(MAXIMUM_CAPACITY),否則就返回擴容後的大小。他只是返回一個size,其實真正的擴容是ensureCapacity這個方法,
*
* <p>This method is called only by putAll.
*/
rivate void ensureCapacity(int numMappings) {
int newCapacity = Collections.roundUpToPowerOfTwo(capacityForInitSize(numMappings));
HashMapEntry<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
if (newCapacity <= oldCapacity) {
return;
}
if (newCapacity == oldCapacity * 2) {
doubleCapacity();
return;
}
// We're growing by at least 4x, rehash in the obvious way
HashMapEntry<K, V>[] newTable = makeTable(newCapacity);
if (size != 0) {
int newMask = newCapacity - 1;
for (int i = 0; i < oldCapacity; i++) {
for (HashMapEntry<K, V> e = oldTable[i]; e != null;) {
HashMapEntry<K, V> oldNext = e.next;
int newIndex = e.hash & newMask;
HashMapEntry<K, V> newNext = newTable[newIndex];
newTable[newIndex] = e;
e.next = newNext;
e = oldNext;
}
}
}
這個方法是私有的,我們看到最上面有個注釋,告訴我們這個方法只能被putAll方法調用,我們再來看一下putAll這個方法
@Override public void putAll(Map<? extends K, ? extends V> map) {
ensureCapacity(map.size());
super.putAll(map);
}
代碼很簡單,我們就不在分析,我們還看上面的ensureCapacity方法,我們來看第5行,這個方法我們上面說過,要必須保證newCapacity是2的n次方,接著看12行,如果初始化的空間大小是原來大小2倍,就會調用doubleCapacity方法,第17行根據newCapacity初始化新數組,第20-29行把原來的從新計算存入到新的數組中,其中第22行取出原來數組下標為i元素的oldNext,23行通過hash值計算e在新數組的下標newIndex,第24行取出新數組下標為newIndex的元素newNext,第25行把原來數組下標為i的元素e存入到新的數組中,26行把原來新數組下標為newIndex的元素newNext掛載到現在新數組下標為newindex的元素下面,可能聽起來比較繞,我們看著上面的圖來說,比如當我們把一個新的元素存放到下標為1的數組中的時候,由於原來這個位置就已經有元素,所以我們把原來這個位置的元素保存起來,然後把新的元素存進去,最後再把原來的這個位置的元素掛載在這個新的元素下面。第27行把上面取出的原來數組的下一個元素賦給e,如果不為空則繼續循環。
HashMap還有一個public V remove(Object key)方法,是根據hash值找到所在的數組位置,然後再根據鏈表的連接和斷開來操作的,這裡就不在詳解,我們來看最後一個方法doubleCapacity,這個方法是設計的精華,一定要認真研讀,
private HashMapEntry<K, V>[] doubleCapacity() {
HashMapEntry<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
//如果原來超過設置的最大值,不在擴容,直接返回
return oldTable;
}
int newCapacity = oldCapacity * 2;//容量擴大2倍
HashMapEntry<K, V>[] newTable = makeTable(newCapacity);
if (size == 0) {//如果原來HashMap的size為0,則直接返回
return newTable;
}
for (int j = 0; j < oldCapacity; j++) {
/*
* Rehash the bucket using the minimum number of field writes.
* This is the most subtle and delicate code in the class.
*/
HashMapEntry<K, V> e = oldTable[j];
if (e == null) {
continue;
}
//下面設計的非常巧妙,我們一定要認真看一下,它首先取得高位的值highBit,
//我們前面已經分析HashMap的容量必須是2的n次方,所以oldCapacity肯定是2的
//n次方,換成二進制就是前面有個1後面全是0,通過hash值的與運輸取得高位,
//然後通過下面的(j | highBit)運輸找到數組的下標,把e存進去,我們仔細
//看highbit通過hash值的與運輸可能為0也可能為1,在之前我們存放的時候都是
//通過hash & (tab.length - 1)計算的,仔細想一下當我們把容量擴大為2倍的時
//候,區別在哪,區別就是在最高位,因為擴大2倍之後最高位往左移動了一位,所以
//這裡面通過計算最高位然後通過與運輸把元素存進去設計的非常好。
int highBit = e.hash & oldCapacity;
HashMapEntry<K, V> broken = null;
newTable[j | highBit] = e;
for (HashMapEntry<K, V> n = e.next; n != null; e = n, n = n.next) {
int nextHighBit = n.hash & oldCapacity;
//下面這些就非常簡單了,就是當前元素下面如果掛載的還有元素就重新排放,
//我們看到是否重新排放判斷的依據是nextHighBit != highBit,這個就非常好
//理解,如果相等說明這兩個元素肯定還位於數組的同一位置以鏈表的形式存在,
//如果不相等肯定位於數組的不同的兩個位置,因為如果不相等也只能是高位不同
//所以判斷的也是高位,舉個例子,比如數組大小為8就是1000,擴大一倍就是16,
//二進制為10000,假如在原來數組的下標為001(二進制),如果不同,那他肯定為
//1001(二進制),高位不同
if (nextHighBit != highBit) {
if (broken == null)
newTable[j | nextHighBit] = n;
else
broken.next = n;
broken = e;
highBit = nextHighBit;
}
}
if (broken != null)
broken.next = null;
}
return newTable;
}
然後剩下的就是HashMap的迭代問題,這個大家自己看看就行了,這裡就不在分析,OK,到目前為止HashMap的源碼就基本分析完了。
 如何在 Android 上運行 ClojureScript
如何在 Android 上運行 ClojureScript
在過去的幾天裡,我有了開發生涯中最有意義的經歷之一, 想在這裡跟大家分享。 現在我們已經讓 ClojureScript 可以在 Android 上運行了。不是在一
 Android EventBus 3.0 框架用法詳解
Android EventBus 3.0 框架用法詳解
看到大家提出的關於Android的問題,有一部分可以用EventBus解決,而也有相當多的人推薦使用EventsBus,因為其和GreenDAO出自一家公司,並
 Android依賴注入之BufferKnife 8.0注解使用
Android依賴注入之BufferKnife 8.0注解使用
前言: App項目開發大部分時候還是以UI頁面為主,這時我們需要調用大量的findViewById以及setOnClickListener等代碼,控件的少的時候我
 Android 網絡圖片查看顯示的實現方法
Android 網絡圖片查看顯示的實現方法
本篇文章小編為大家介紹,Android 網絡圖片查看顯示的實現方法,需要的朋友參考下。 我們的應用或多或少都會從網絡獲取圖片數據然後進行顯示,下面就將實現一個這樣