編輯:關於Android編程
1.jsoup介紹
很多時候,我們需要從各種網頁上面抓取數據,而jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文本內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似於jQuery的操作方法來取出和操作數據。
jsoup官方文檔:https://jsoup.org/cookbook/
2.使用場景
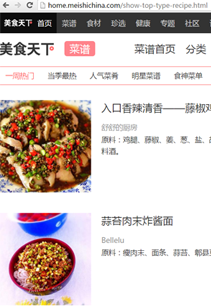
下面是一張關於美食的截圖,可以留意到這是一個html網頁,當我們想要抓取裡面的數據的時候,jsoup就能幫到我們很多。
接下來開始手把手教學
首先,也是很重要的一步,就是下載jar包,丟到libs裡面
jar包下載地址:http://jsoup.org/download
Android studio玩家可以不下載jar包,在Gradle裡面加入
dependencies {
compile 'org.jsoup:jsoup:1.9.2'
}
然後,找到你心儀的網頁去抓取數據
這裡我們我繼續使用美食的網頁,然後右鍵查看網頁源碼,或者按F12,接下來可以看到一大堆標簽:

找到需要的,例如上圖這個 “美食天下” ,可以看到 “美食天下” 是放在以 <div class="top-bar" id="J_top_bar"> 為節點的 <a title="美食天下" 中,要獲取這個“美食天下”,代碼可以這樣寫:
try {
//從一個URL加載一個Document對象。
Document doc = Jsoup.connect("http://home.meishichina.com/show-top-type-recipe.html").get();
//選擇“美食天下”所在節點
Elements elements = doc.select("div.top-bar");
//打印 <a>標簽裡面的title
Log.i("mytag",elements.select("a").attr("title"));
}catch(Exception e) {
Log.i("mytag", e.toString());
}
接下來看一下打印出來的結果:
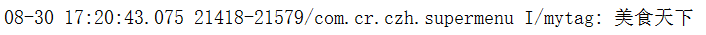
Jsoup.connect(String url)方法從一個URL加載一個Document對象。如果從該URL獲取HTML時發生錯誤,便會拋出 IOException,應適當處理。
一旦擁有了一個Document,你就可以使用Document中適當的方法或它父類 Element和Node中的方法來取得相關數據。
public class Element extends Node public class Document extends Element
很多文章都是說一大堆原理然後放出一個簡單的例子,就跟我上面簡單的打了一個log一樣,然後發現用起來的時候是沒那麼簡單的。為了大家能不看文檔也可以直接使用(並且看不懂那一大堆標簽也可以用),我決定再舉一個例子(其實也就是比上面多打幾個log):
下圖紅色框框是我們要獲取的數據,可以看到他們對應的節點就是藍色圓圈裡面的<div class="xxx">

廢話不多說上代碼
try {
//還是一樣先從一個URL加載一個Document對象。
Document doc = Jsoup.connect("http://home.meishichina.com/show-top-type-recipe.html").get();
//“椒麻雞”和它對應的圖片都在<div class="pic">中
Elements titleAndPic = doc.select("div.pic");
//使用Element.select(String selector)查找元素,使用Node.attr(String key)方法取得一個屬性的值
Log.i("mytag", "title:" + titleAndPic.get(1).select("a").attr("title") + "pic:" + titleAndPic.get(1).select("a").select("img").attr("data-src"));
//所需鏈接在<div class="detail">中的<a>標簽裡面
Elements url = doc.select("div.detail").select("a");
Log.i("mytag", "url:" + url.get(i).attr("href"));
//原料在<p class="subcontent">中
Elements burden = doc.select("p.subcontent");
//對於一個元素中的文本,可以使用Element.text()方法
Log.i("mytag", "burden:" + burden.get(1).text());
}catch(Exception e) {
Log.i("mytag", e.toString());
}
大功告成,接下來看看log
沒有問題!那麼教學可以結束了!
注意:
Jsoup.connect(String url)方法不能運行在主線程,否則會報NetworkOnMainThreadException
最後上一張應用在項目的效果圖:
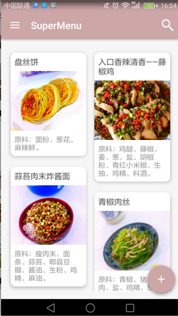
有沒有發現熟悉的椒麻雞?很酷炫有木有!
小結
整堂課分幾步:
1.下載jar包並丟到libs(或者在gradle)
2.找到心儀的網頁
3.用Jsoup.connect()獲取網頁的document
4.查看網頁源碼,對准你想要的地方,給他來一個Element.select(String selector)
5.用Node.attr(String key)或者Element.text()方法把數據抽出來
6.沒有6了就是這麼簡單!
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持本站。
 Android開發技巧之像QQ一樣輸入文字和表情圖像
Android開發技巧之像QQ一樣輸入文字和表情圖像
EditText和TextView一樣,也可以進行圖文混排。所不同的是,TextView只用於顯示圖文混排效果,而EditText不僅可顯示,也可混合輸入文字和圖像,讓我
 Android:AppWidget之桌面小電筒
Android:AppWidget之桌面小電筒
安卓開發中很多控件都是Widget類的,但是我們常說的Widget指的是AppWidget,即一些可以放置在桌面的小部件。 下面用兩個實例來說一下這個AppWid
 微信小程序 實現列表刷新的實例詳解
微信小程序 實現列表刷新的實例詳解
微信小程序 列表刷新: 微信小程序,最近自己學習微信
 Android listview ExpandableListView實現多選,單選,全選,edittext實現批量輸入的實例代碼
Android listview ExpandableListView實現多選,單選,全選,edittext實現批量輸入的實例代碼
最近在項目開發中,由於項目的需求要實現一些列表的單選,多選,全選,批量輸入之類的功能,其實功能的實現倒不是很復雜,需求中也沒有涉及到復雜的動畫什麼之類,主要是解決列表數據