編輯:Android資訊
分析源碼之前先來介紹一下ArrayMap的存儲結構,ArrayMap數據的存儲不同於HashMap和SparseArray,在上一篇《Android SparseArray源碼詳解》中我們講到SparseArray是以純數組的形式存儲的,一個數組存儲的是key值一個數組存儲的是value值,今天我們分析的ArrayMap和SparseArray有點類似,他也是以純數組的形式存儲,不過不同的是他的一個數組存儲的是Hash值另一個數組存儲的是key和value,其中key和value是成對出現的,key存儲在數組的偶數位上,value存儲在數組的奇數位上,我們先來看其中的一個構造方法
public ArrayMap(int capacity) {
if (capacity == 0) {
mHashes = ContainerHelpers.EMPTY_INTS;
mArray = ContainerHelpers.EMPTY_OBJECTS;
} else {
allocArrays(capacity);
}
mSize = 0;
}
當capacity不為0的時候調用allocArrays方法分配數組大小,在分析allocArrays源碼之前,我們先來看一下freeArrays方法,
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {
if (hashes.length == (BASE_SIZE*2)) {
synchronized (ArrayMap.class) {
if (mTwiceBaseCacheSize < CACHE_SIZE) {
array[0] = mTwiceBaseCache;
array[1] = hashes;
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;
}
mTwiceBaseCache = array;
mTwiceBaseCacheSize++;
if (DEBUG) Log.d(TAG, "Storing 2x cache " + array
+ " now have " + mTwiceBaseCacheSize + " entries");
}
}
} else if (hashes.length == BASE_SIZE) {
synchronized (ArrayMap.class) {
if (mBaseCacheSize < CACHE_SIZE) {
array[0] = mBaseCache;
array[1] = hashes;
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;
}
mBaseCache = array;
mBaseCacheSize++;
if (DEBUG) Log.d(TAG, "Storing 1x cache " + array
+ " now have " + mBaseCacheSize + " entries");
}
}
}
}
BASE_SIZE的值為4,ArrayMap對於hashes.length為4和8的兩種情況會進行緩存,上面的兩種情況下原理都是一樣的,我們就用下面的一種情況進行分析,緩存的數量也不是無線大的,當大於等於10(CACHE_SIZE)的時候也就不再進行緩存了,緩存的原理就是讓array數組的第一個位置保存之前緩存的mBaseCache,第二個位置保存當前的hashes數組,其他的全部置為空,下面我們再來看一下之前的allocArrays方法,
private void allocArrays(final int size) {
if (mHashes == EMPTY_IMMUTABLE_INTS) {
throw new UnsupportedOperationException("ArrayMap is immutable");
}
if (size == (BASE_SIZE*2)) {
………………………
} else if (size == BASE_SIZE) {
synchronized (ArrayMap.class) {
if (mBaseCache != null) {
final Object[] array = mBaseCache;
mArray = array;
mBaseCache = (Object[])array[0];
mHashes = (int[])array[1];
array[0] = array[1] = null;
mBaseCacheSize--;
if (DEBUG) Log.d(TAG, "Retrieving 1x cache " + mHashes
+ " now have " + mBaseCacheSize + " entries");
return;
}
}
}
mHashes = new int[size];
mArray = new Object[size<<1];
}
如果分配的尺寸不為4或者8,就初始化,我們看到最下面兩行mArray的大小是mHashes的兩倍,這是因為mArray存儲的是key和value兩個值。如果分配的尺寸為4或者8,就判斷之前對這兩種情況是否進行了緩存,如果緩存過就從緩存中取,取出來的時候會把array的值置空,在上面的freeArrays方法中我們知道array的第一個位置和第二個位置保存的有值,其他的都置為空,在這裡把array[0]和array[1]也置為了空,但是有一點奇葩的地方就是mHashes的值確保留了下來,無論是在freeArrays方法中還是在allocArrays方法中,都沒有把他置為默認值。通過ArrayMap的源碼發現,這裡mHashes的值無論改不改變基本上都沒有什麼太大影響,因為put的時候如果存在就被替換了,但在indexOf的方法中如果存在還要在繼續比較key的值,只有hash和key都一樣才會返回。我們下面來看一下indexOf(Object key, int hash)這個方法,
int indexOf(Object key, int hash) {
final int N = mSize;
// Important fast case: if nothing is in here, nothing to look for.
if (N == 0) {
return ~0;
}
int index = ContainerHelpers.binarySearch(mHashes, N, hash);
// If the hash code wasn't found, then we have no entry for this key.
if (index < 0) {
return index;
}
// If the key at the returned index matches, that's what we want.
if (key.equals(mArray[index<<1])) {
return index;
}
// Search for a matching key after the index.
int end;
for (end = index + 1; end < N && mHashes[end] == hash; end++) {
if (key.equals(mArray[end << 1])) return end;
}
// Search for a matching key before the index.
for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {
if (key.equals(mArray[i << 1])) return i;
}
// Key not found -- return negative value indicating where a
// new entry for this key should go. We use the end of the
// hash chain to reduce the number of array entries that will
// need to be copied when inserting.
return ~end;
}
這個方法很簡單,就是根據二分法查找來確定hash值在數組中的位置,如果沒找到就返回一個負數,注意下面還有兩個循環,這是因為mHashes數組中的hash值不是唯一的,只有hash值相同並且key也相同才會返回所在的位置,否則就返回一個負數。下面就來看一下put(K key, V value)這個方法。
@Override
public V put(K key, V value) {
final int hash;
int index;
if (key == null) {
hash = 0;
index = indexOfNull();
} else {
hash = key.hashCode();
index = indexOf(key, hash);
}
//通過查找,如果找到就把原來的替換,
if (index >= 0) {
index = (index<<1) + 1;
final V old = (V)mArray[index];
mArray[index] = value;
return old;
}
//在上一篇《Android SparseArray源碼詳解》講過,根據二分法查找,如果沒有找到就會返回一個負數,這裡進行取反
index = ~index;
//如果滿了就擴容
if (mSize >= mHashes.length) {
//擴容的尺寸,三目運算符
final int n = mSize >= (BASE_SIZE*2) ? (mSize+(mSize>>1))
: (mSize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
//擴容
allocArrays(n);
//如果原來有數據就把原來的數據拷貝到擴容後的數組中
if (mHashes.length > 0) {
if (DEBUG) Log.d(TAG, "put: copy 0-" + mSize + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
freeArrays(ohashes, oarray, mSize);
}
//根據上面的二分法查找,如果index小於mSize,說明新的數據是插入到數組之間index位置,插入之前需要把後面的移位
if (index < mSize) {
if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (mSize-index)
+ " to " + (index+1));
System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index);
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
//數據保存,mHashes只有hash值,mArray即保存key值又保存value值,
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}
還有clear()方法和erase()方法,這兩個區別就是clear()把所有的數據清空,並釋放空間,erase()清空數據但沒有釋放空間,並且erase()只清mArray數據,mHashes數據並沒有清空,這就是上面講到的mHashes即使沒清空也不會有影響,代碼比較少就不在看了。在看一下和put類似的一個方法append(K key, V value)
/**
* Special fast path for appending items to the end of the array without validation.
* The array must already be large enough to contain the item.
* @hide
*/
public void append(K key, V value) {
int index = mSize;
final int hash = key == null ? 0 : key.hashCode();
if (index >= mHashes.length) {
throw new IllegalStateException("Array is full");
}
if (index > 0 && mHashes[index-1] > hash) {
RuntimeException e = new RuntimeException("here");
e.fillInStackTrace();
Log.w(TAG, "New hash " + hash
+ " is before end of array hash " + mHashes[index-1]
+ " at index " + index + " key " + key, e);
put(key, value);
return;
}
mSize = index+1;
mHashes[index] = hash;
index <<= 1;
mArray[index] = key;
mArray[index+1] = value;
}
我們看注釋這個方法是隱藏的,沒有開放,因為這個方法不穩定,如果調用可能就會出現問題,看上面的注釋,意思是說這個方法存儲數據的時候沒有驗證,因為在最後存儲的時候,是直接存進去的,這就會有一個問題,如果之前存過相同的key和value,再調用這個方法,很可能會再次存入,就可能會有兩個key和value完全一樣的,我個人認為如果把上面的if (index > 0 && mHashes[index-1] > hash)改為if (index > 0 && mHashes[index-1] >= hash)應該就沒問題了,因為如果有相同的就調用put方法把原來的替換,不明白他為什麼要這樣寫,下面再看一個方法validate()
/**
* The use of the {@link #append} function can result in invalid array maps, in particular
* an array map where the same key appears multiple times. This function verifies that
* the array map is valid, throwing IllegalArgumentException if a problem is found. The
* main use for this method is validating an array map after unpacking from an IPC, to
* protect against malicious callers.
* @hide
*/
public void validate() {
final int N = mSize;
if (N <= 1) {
// There can't be dups.
return;
}
int basehash = mHashes[0];
int basei = 0;
for (int i=1; i<N; i++) {
int hash = mHashes[i];
if (hash != basehash) {
basehash = hash;
basei = i;
continue;
}
// We are in a run of entries with the same hash code. Go backwards through
// the array to see if any keys are the same.
final Object cur = mArray[i<<1];
for (int j=i-1; j>=basei; j--) {
final Object prev = mArray[j<<1];
if (cur == prev) {
throw new IllegalArgumentException("Duplicate key in ArrayMap: " + cur);
}
if (cur != null && prev != null && cur.equals(prev)) {
throw new IllegalArgumentException("Duplicate key in ArrayMap: " + cur);
}
}
}
}
看上面的注釋也是隱藏的,存儲的時候可能會存在多個相同的key,這個方法就是用來驗證的,這個方法很好理解,因為我們存儲數據的時候是按照二分法查找然後存儲的,如果hash值相同,那麼存儲的時候肯定是挨著的,在這裡進行驗證,對挨著相同hash值的數據進行key比較,如果key相同,則說明已經存在了,就會報異常。我們再來看最後一個方法
public V removeAt(int index) {
final Object old = mArray[(index << 1) + 1];
//如果小於等於1就全部清空
if (mSize <= 1) {
// Now empty.
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to 0");
freeArrays(mHashes, mArray, mSize);
mHashes = EmptyArray.INT;
mArray = EmptyArray.OBJECT;
mSize = 0;
} else {
// 如果數組比較大,但使用的比較少,就會重新分配空間
if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {
// Shrunk enough to reduce size of arrays. We don't allow it to
// shrink smaller than (BASE_SIZE*2) to avoid flapping between
// that and BASE_SIZE.
//重新計算空間,當大於8的時候會1.5倍增長
final int n = mSize > (BASE_SIZE*2) ? (mSize + (mSize>>1)) : (BASE_SIZE*2);
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
// 重新分配空間
allocArrays(n);
mSize--;
if (index > 0) {
//如果刪除的位置大於0,拷貝前半部分到新數組中
if (DEBUG) Log.d(TAG, "remove: copy from 0-" + index + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, index);
System.arraycopy(oarray, 0, mArray, 0, index << 1);
}
if (index < mSize) {
// 如果刪除的位置小於mSize,把index位置以後的數據拷貝到新數組中
if (DEBUG) Log.d(TAG, "remove: copy from " + (index+1) + "-" + mSize
+ " to " + index);
System.arraycopy(ohashes, index + 1, mHashes, index, mSize - index);
System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,
(mSize - index) << 1);
}
} else {
mSize--;
if (index < mSize) {
//同上
if (DEBUG) Log.d(TAG, "remove: move " + (index+1) + "-" + mSize
+ " to " + index);
System.arraycopy(mHashes, index + 1, mHashes, index, mSize - index);
System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,
(mSize - index) << 1);
}
// 把移除的位置置空,上面的為什麼沒有置空,是因為上面的數據拷貝到一個新的數組中,而刪除的就沒有
//拷貝,這裡要置空是因為這裡數組沒有擴容,還是在原來的數組操作,所以必須置空
mArray[mSize << 1] = null;
mArray[(mSize << 1) + 1] = null;
}
}
return (V)old;
}
剩下的方法都比較簡單,這裡就不在一一分析。
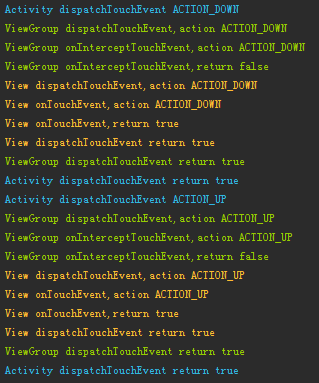 更簡單的學習Android事件分發
更簡單的學習Android事件分發
事件分發是Android中非常重要的機制,是用戶與界面交互的基礎。這篇文章將通過示例打印出的Log,繪制出事件分發的流程圖,讓大家更容易的去理解Android的事
 改變Android按鈕背景顏色的高效方法
改變Android按鈕背景顏色的高效方法
本文由碼農網 – 小峰原創翻譯,轉載請看清文末的轉載要求,歡迎參與我們的付費投稿計劃! 本文將介紹一種有效改變Android按鈕顏色的方法。 按鈕可以在狀
 Android UI控件系列:TabWidget(切換卡)
Android UI控件系列:TabWidget(切換卡)
Tab選項卡類似與電話本的界面,通過多個標簽切換不同的內容,要實現這個效果,首先要知道TabHost,它是一個用來存放多個Tab標簽的容器,每一個Tab都可以對應
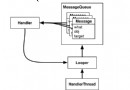 Android Handler Looper Message 詳細分析
Android Handler Looper Message 詳細分析
Android異步消息機制架構 Android異步消息處理架構,其實沒那麼復雜。簡單來說就是 looper 對象擁有 message queue ,並且負責從 m