如何防止HA集群的腦裂
1. 引言
腦裂(split-brain),指在一個高可用(HA)系統中,當聯系著的兩個節點斷開聯系時,本來為一個整體的系統,分裂為兩個獨立節點,這時兩個節點開始爭搶共享資源,結果會導致系統混亂,數據損壞。
對於無狀態服務的HA,無所謂腦裂不腦裂;但對有狀態服務(比如MySQL)的HA,必須要嚴格防止腦裂。(但有些生產環境下的系統按照無狀態服務HA的那一套去配置有狀態服務,結果可想而知...)
2. 如何防止HA集群腦裂
一般采用2個方法
1. 仲裁
當兩個節點出現分歧時,由第3方的仲裁者決定聽誰的。這個仲裁者,可能是一個鎖服務,一個共享盤或者其它什麼東西。
2. fencing
當不能確定某個節點的狀態時,通過fencing把對方干掉,確保共享資源被完全釋放,前提是必須要有可靠的fence設備。
理想的情況下,以上兩者一個都不能少。
但是,如果節點沒有使用共享資源,比如基於主從復制的數據庫HA,我們也可以安全的省掉fence設備,只保留仲裁。而且很多時候我們的環境裡也沒有可用的fence設備,比如在雲主機裡。
那麼可不可以省掉仲裁,只留fence設備呢?
不可以。因為,當兩個節點互相失去聯絡時會同時fencing對方。如果fencing的方式是reboot,那麼兩台機器就會不停的重啟。如果fencing的方式是power off,那麼結局有可能是2個節點同歸於盡,也有可能活下來一個。但是如果兩個節點互相失去聯絡的原因是其中一個節點的網卡故障,而活下來的正好又是那個有故障的節點,那麼結局一樣是悲劇。
所以,單純的雙節點,無論如何也防止不了腦裂。
3. 沒有fence設備是否安全
以PostgreSQL或MySQL的數據復制為例來說明這個問題。
在基於復制的場景下,主從節點沒有共享資源,所以2個節點都活著本身沒有問題。問題是客戶端會不會訪問到本該死掉的那個節點。這又牽扯到客戶端路由的問題。
客戶端路由有幾種方式,基於VIP,基於Proxy,基於DNS或者干脆客戶端維護一個服務端地址列表自己判斷主從。不管采用哪種方式,主從切換的時候都要更新路由。
基於DNS的路由是不太靠譜的,因為DNS可能會被客戶端緩存,很難清干淨。
基於VIP的路由有一些變數,如果本該死掉的節點沒有摘掉自己身上的VIP,那麼它隨時可能出來搗亂(即使新主已經通過arping更新了所有主機上的arp緩存,如果某個主機的arp過期,發一個arp查詢,那麼就會發生ip沖突)。所以可以認為VIP也是一種特殊的共享資源,必需把它從故障節點上摘掉。至於怎麼摘,最簡單的辦法就是故障節點發現自己失聯後自己摘,如果它還活著的話(如果它死了,也就不用摘了)。如果負責摘vip的進程無法工作怎麼辦?這時候就可以用上本來不太靠譜的軟fence設備了(比如ssh)。
基於Proxy的路由是比較靠譜的,因為Proxy是唯一的服務入口,只要把Proxy一個地方更新了,就不會發生客戶端誤訪問的問題了,但是也要考慮Proxy的高可用。
至於基於服務端地址列表的方法,客戶端需要通過後台服務判斷主從(比如PostgreSQL/MySQL會話是否處於只讀模式)。這時,如果出現2個主,客戶端就會錯亂。為防止這個問題,原主節點發現自己失聯後要自己把服務停掉,這和前面摘vip的道理是一樣的。
因此,為了不讓故障節點搗亂,故障節點應該在失聯後自己釋放資源,為了應對釋放資源的進程本身出現故障,可以加上軟fence。在這個前提下,可以認為沒有可靠的物理fence設備也是安全的。
4. 主從切換後數據能否保證不丟
主從切換後數據會不會丟和腦裂可以認為是2個不同的問題。還以PostgreSQL或MySQL的數據復制為例來說明。
對PostgreSQL,如果配置成同步流復制,可以做到不管路由是否正確,都不會丟數據。因為路由到錯誤節點的客戶端根本寫不進任何數據,它會一直等待從節點的反饋,而它以為的從節點,現在已經是主子了,當然不會理它。當然如果老是這樣也不好,但它給集群監視軟件糾正路由錯誤提供了充足的時間。
對MySQL,即使配置成半同步復制,在超時發生後,它可能會自動降級為異步復制。為了防止MySQL的復制降級,可以設置一個超大的rpl_semi_sync_master_timeout,同時保持rpl_semi_sync_master_wait_no_slave為on(即默認值)。但是,這時如果從宕了,主也會hang住。這個問題的破解方法和PostgreSQL是一樣的,或者配置成1主2從,只要不是2個從都宕機就沒事,或者由外部的集群監視軟件動態切換半同步和異步。
如果本來就是配置的異步復制,那就是說已經做好丟數據的准備了。這時候,主從切換時丟點數據也沒啥大不了,但要控制自動切換的次數。比如控制已經被failover掉的原主不允許自動上線,否則如果因為網絡抖動導致故障切換,那麼主從就會不停的來回切,不停的丟數據,破壞數據的一致性。
5. 如何實現上面的策略
你可以自己完全從頭開始實現一套符合上述邏輯的腳本。但我更傾向於基於成熟的集群軟件去搭建,比如Pacemaker+Corosync+合適的資源Agent。Keepalived我是極不推薦的,它就不適合用於有狀態服務的HA,即使你把仲裁,fence那些東西都加到方案裡,總覺得別扭。
使用Pacemaker+Corosync的方案也有一些注意事項
1)了解資源Agent的功能和原理
了解資源Agent的功能和原理,才能知道它適用的場景。比如pgsql的資源Agent是比較完善的,支持同步和異步流復制,並且可以在兩者之前自動切換,並且可以保證同步復制下數據不會丟失。但目前MySQL的資源Agent就很弱了,沒有使用GTID又沒有日志補償,很容易丟數據,還是不要用的好,繼續用MHA吧(但是,部署MHA時務必要防范腦裂)。
2)確保法定票數(quorum)
quorum可以認為是Pacemkaer自帶的仲裁機制,集群的所有節點中的多數選出一個協調者,集群的所有指令都由這個協調者發出,可以完美的杜絕腦裂問題。為了使這套機制有效運轉,集群中至少有3個節點,並且把no-quorum-policy設置成stop,這也是默認值。(很多教程為了方便演示,都把no-quorum-policy設置成ignore,生產環境如果也這麼搞,又沒有其它仲裁機制,是很危險的!)
但是,如果只有2個節點該怎麼辦?
一是拉一個機子借用一下湊足3個節點,再設置location限制,不讓資源分配到那個節點上。
二是把多個不滿足quorum小集群拉到一起,組成一個大的集群,同樣適用location限制控制資源的分配的位置。
但是如果你有很多雙節點集群,找不到那麼多用於湊數的節點,又不想把這些雙節點集群拉到一起湊成一個大的集群(比如覺得不方便管理)。那麼可以考慮第三種方法。
第三種方法是配置一個搶占資源,以及服務和這個搶占資源的colocation約束,誰搶到搶占資源誰提供服務。這個搶占資源可以是某個鎖服務,比如基於zookeeper包裝一個,或者干脆自己從頭做一個,就像下面這個例子。
http://my.oschina.net/hanhanztj/blog/515065
(這個例子是基於http協議的短連接,更細致的做法是使用長連接心跳檢測,這樣服務端可以及時檢出連接斷開而釋放鎖)
但是,一定要同時確保這個搶占資源的高可用,可以把提供搶占資源的服務做成lingyig高可用的,也可以簡單點,部署3個服務,雙節點上個部署一個,第三個部署在另外一個專門的仲裁節點上,至少獲取3個鎖中的2個才視為取得了鎖。這個仲裁節點可以為很多集群提供仲裁服務(因為一個機器只能部署一個Pacemaker實例,否則可以用部署了N個Pacemaker實例的仲裁節點做同樣的事情。)。但是,如非迫不得已,盡量還是采用前面的方法,即滿足Pacemaker法定票數,這種方法更簡單,可靠。
6.參考
http://blog.chinaunix.net/uid-20726500-id-4461367.html
http://my.oschina.net/hanhanztj/blog/515065
http://clusterlabs.org/doc/en-US/Pacemaker/1.1-plugin/html-single/Pacemaker_Explained/index.html
http://clusterlabs.org/wiki/PgSQL_Replicated_Cluster
http://mysqllover.com/?p=799
http://gmt-24.net/archives/1077
 Android基礎入門教程——9.2 MediaPlayer播放音頻與視頻
Android基礎入門教程——9.2 MediaPlayer播放音頻與視頻
 【騰訊Bugly干貨分享】微信Tinker的一切都在這裡,包括源碼(一),buglytinker
【騰訊Bugly干貨分享】微信Tinker的一切都在這裡,包括源碼(一),buglytinker
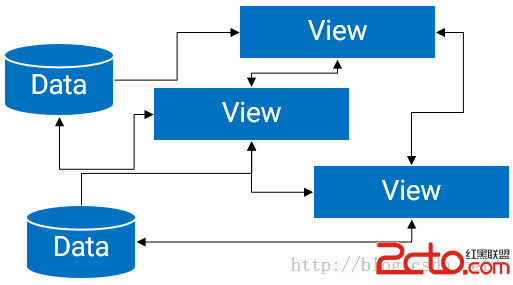 Android MVP開發模式詳解(十九)
Android MVP開發模式詳解(十九)
 Android開發學習之路-DiffUtil使用教程,android-diffutil
Android開發學習之路-DiffUtil使用教程,android-diffutil