編輯:關於Android編程
在Android平台上可以使用Simple API for XML(SAX) 、 Document Object Model(DOM)和Android附帶的pull解析器解析XML文件。
下面是本例子要解析的XML文件:itcast.xml
李明 30李向梅 25
public class Person {
private Integer id;
private String name;
private Short age;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Short getAge() {
return age;
}
public void setAge(Short age) {
this.age = age;
}
}
1. SAX解析XML文件
SAX是一個解析速度快並且占用內存少的xml解析器,非常適合用於Android等移動設備。 SAX解析XML文件采用的是事件驅動,也就是說,它並不需要解析完整個文檔,在按內容順序解析文檔的過程中,SAX會判斷當前讀到的字符是否合法XML語法中的某部分,如果符合就會觸發事件。所謂事件,其實就是一些回調(callback)方法,這些方法(事件)定義在ContentHandler接口。
public static ListreadXML(InputStream inStream) { try { //創建解析器 SAXParserFactory spf = SAXParserFactory.newInstance(); SAXParser saxParser = spf.newSAXParser(); //設置解析器的相關特性,true表示開啟命名空間特性 saxParser.setProperty("http://xml.org/sax/features/namespaces",true); XMLContentHandler handler = new XMLContentHandler(); saxParser.parse(inStream, handler); inStream.close(); return handler.getPersons(); } catch (Exception e) { e.printStackTrace(); } return null; } //SAX類:DefaultHandler,它實現了ContentHandler接口。在實現的時候,只需要繼承該類,重載相應的方法即可。 public class XMLContentHandler extends DefaultHandler { private List persons = null; private Person currentPerson; private String tagName = null;//當前解析的元素標簽 public List getPersons() { return persons; } //接收文檔開始的通知。當遇到文檔的開頭的時候,調用這個方法,可以在其中做一些預處理的工作。 @Override public void startDocument() throws SAXException { persons = new ArrayList (); } //接收元素開始的通知。當讀到一個開始標簽的時候,會觸發這個方法。其中namespaceURI表示元素的命名空間; //localName表示元素的本地名稱(不帶前綴);qName表示元素的限定名(帶前綴);atts 表示元素的屬性集合 @Override public void startElement(String namespaceURI, String localName, String qName, Attributes atts) throws SAXException { if(localName.equals("person")){ currentPerson = new Person(); currentPerson.setId(Integer.parseInt(atts.getValue("id"))); } this.tagName = localName; } //接收字符數據的通知。該方法用來處理在XML文件中讀到的內容,第一個參數用於存放文件的內容, //後面兩個參數是讀到的字符串在這個數組中的起始位置和長度,使用new String(ch,start,length)就可以獲取內容。 @Override public void characters(char[] ch, int start, int length) throws SAXException { if(tagName!=null){ String data = new String(ch, start, length); if(tagName.equals("name")){ this.currentPerson.setName(data); }else if(tagName.equals("age")){ this.currentPerson.setAge(Short.parseShort(data)); } } } //接收文檔的結尾的通知。在遇到結束標簽的時候,調用這個方法。其中,uri表示元素的命名空間; //localName表示元素的本地名稱(不帶前綴);name表示元素的限定名(帶前綴) @Override public void endElement(String uri, String localName, String name) throws SAXException { if(localName.equals("person")){ persons.add(currentPerson); currentPerson = null; } this.tagName = null; } }
2. DOM解析XML文件
DOM解析XML文件時,會將XML文件的所有內容讀取到內存中,然後允許您使用DOM API遍歷XML樹、檢索所需的數據。使用DOM操作XML的代碼看起來比較直觀,並且,在某些方面比基於SAX的實現更加簡單。但是,因為DOM需要將XML文件的所有內容讀取到內存中,所以內存的消耗比較大,特別對於運行Android的移動設備來說,因為設備的資源比較寶貴,所以建議還是采用SAX來解析XML文件,當然,如果XML文件的內容比較小采用DOM是可行的。
public static ListreadXML(InputStream inStream) { List persons = new ArrayList (); DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); try { DocumentBuilder builder = factory.newDocumentBuilder(); Document dom = builder.parse(inStream); Element root = dom.getDocumentElement(); NodeList items = root.getElementsByTagName("person");//查找所有person節點 for (int i = 0; i < items.getLength(); i++) { Person person = new Person(); //得到第一個person節點 Element personNode = (Element) items.item(i); //獲取person節點的id屬性值 person.setId(new Integer(personNode.getAttribute("id"))); //獲取person節點下的所有子節點(標簽之間的空白節點和name/age元素) NodeList childsNodes = personNode.getChildNodes(); for (int j = 0; j < childsNodes.getLength(); j++) { Node node = (Node) childsNodes.item(j); //判斷是否為元素類型 if(node.getNodeType() == Node.ELEMENT_NODE){ Element childNode = (Element) node; //判斷是否name元素 if ("name".equals(childNode.getNodeName())) { //獲取name元素下Text節點,然後從Text節點獲取數據 person.setName(childNode.getFirstChild().getNodeValue()); } else if (“age”.equals(childNode.getNodeName())) { person.setAge(new Short(childNode.getFirstChild().getNodeValue())); } } } persons.add(person); } inStream.close(); } catch (Exception e) { e.printStackTrace(); } return persons; }
3.Pull解析器解析XML文件
Pull解析器的運行方式與 SAX 解析器相似。它提供了類似的事件,如:開始元素和結束元素事件,使用parser.next()可以進入下一個元素並觸發相應事件。事件將作為數值代碼被發送,因此可以使用一個switch對感興趣的事件進行處理。當元素開始解析時,調用parser.nextText()方法可以獲取下一個Text類型元素的值。
//讀取XML public static ListreadXML(InputStream inStream) { XmlPullParser parser = Xml.newPullParser(); try { parser.setInput(inStream, "UTF-8"); int eventType = parser.getEventType(); Person currentPerson = null; List persons = null; while (eventType != XmlPullParser.END_DOCUMENT) { switch (eventType) { case XmlPullParser.START_DOCUMENT://文檔開始事件,可以進行數據初始化處理 persons = new ArrayList (); break; case XmlPullParser.START_TAG://開始元素事件 String name = parser.getName(); if (name.equalsIgnoreCase("person")) { currentPerson = new Person(); currentPerson.setId(new Integer(parser.getAttributeValue(null, "id"))); } else if (currentPerson != null) { if (name.equalsIgnoreCase("name")) { currentPerson.setName(parser.nextText());// 如果後面是Text元素,即返回它的值 } else if (name.equalsIgnoreCase("age")) { currentPerson.setAge(new Short(parser.nextText())); } } break; case XmlPullParser.END_TAG://結束元素事件 if (parser.getName().equalsIgnoreCase("person") && currentPerson != null) { persons.add(currentPerson); currentPerson = null; } break; } eventType = parser.next(); } inStream.close(); return persons; } catch (Exception e) { e.printStackTrace(); } return null; } //成XML文件 //使用Pull解析器生成一個與itcast.xml文件內容相同的myitcast.xml文件。 public static String writeXML(List persons, Writer writer){ XmlSerializer serializer = Xml.newSerializer(); try { serializer.setOutput(writer); serializer.startDocument("UTF-8", true); //第一個參數為命名空間,如果不使用命名空間,可以設置為null serializer.startTag("", "persons"); for (Person person : persons){ serializer.startTag("", "person"); serializer.attribute("", "id", person.getId().toString()); serializer.startTag("", "name"); serializer.text(person.getName()); serializer.endTag("", "name"); serializer.startTag("", "age"); serializer.text(person.getAge().toString()); serializer.endTag("", "age"); serializer.endTag("", "person"); } serializer.endTag("", "persons"); serializer.endDocument(); return writer.toString(); } catch (Exception e) { e.printStackTrace(); } return null; } //使用代碼如下(生成XML文件): File xmlFile = new File("myitcast.xml"); FileOutputStream outStream = new FileOutputStream(xmlFile); OutputStreamWriter outStreamWriter = new OutputStreamWriter(outStream, "UTF-8"); BufferedWriter writer = new BufferedWriter(outStreamWriter); writeXML(persons, writer); writer.flush(); writer.close(); //如果只想得到生成的xml內容,可以使用StringWriter: StringWriter writer = new StringWriter(); writeXML(persons, writer); String content = writer.toString();
4.SAX和PULL使用
區別為:SAX解析器的工作方式是自動將事件推入事件處理器進行處理,因此你不能控制事件的處理主動結束;而Pull解析器的工作方式為允許你的應用程序代碼主動從解析器中獲取事件,正因為是主動獲取事件,因此可以在滿足了需要的條件後不再獲取事件,結束解析。
你隨便找個sax和pull的例子比較一下就可以發現,pull是一個while循環,隨時可以跳出,而sax不是,sax是只要解析了,就必須解析完成。
 android Handler Looper,MessageQueue消息機制原理
android Handler Looper,MessageQueue消息機制原理
安卓消息處理類:Looper、Handler、MessageQueue、Message、ThreadLocal、ThreadLocal.Values、HandlerThr
 CMD 使用emulator.exe啟動Android模擬器——emulator -data 鏡像文件名稱
CMD 使用emulator.exe啟動Android模擬器——emulator -data 鏡像文件名稱
在命令行[CMD]使用emulator.exe啟動Android模擬器兩種方式:- emulator -avd (AVD名稱)- emulator -data (鏡像文件
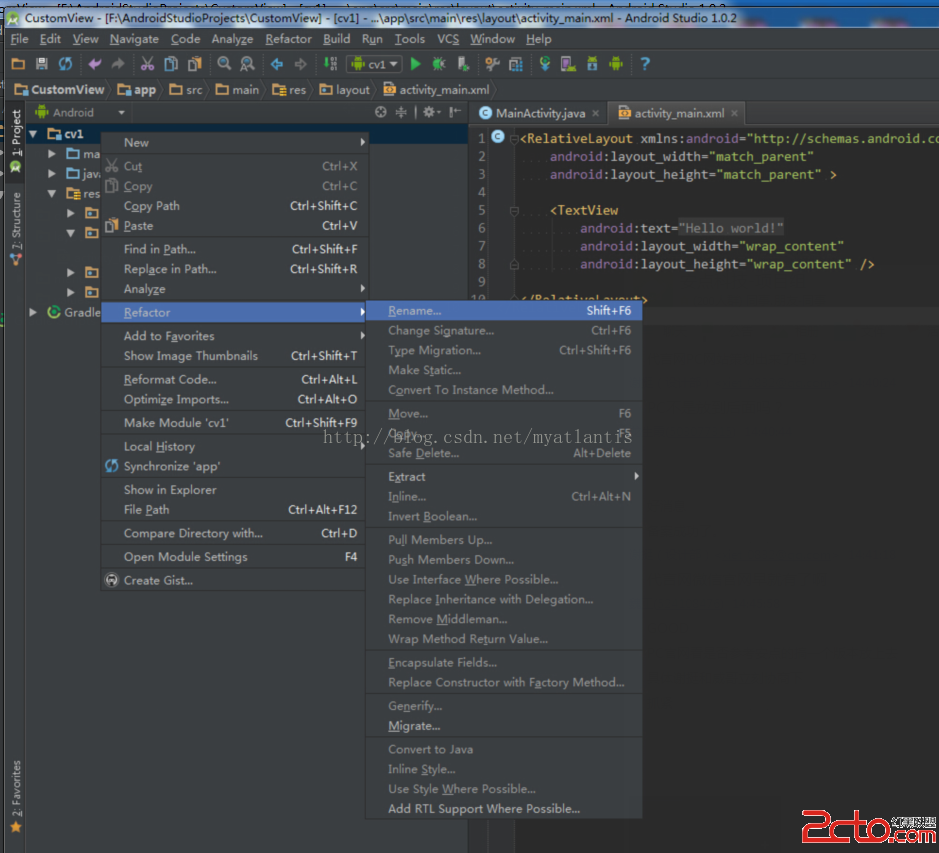 Android Studio之修改module名稱
Android Studio之修改module名稱
當我們第一次創建一個project,Android Studio會自動幫我們創建一個app的module,這裡的module相當於Eclipse中的project,只是A
 安卓技巧三星Galaxy SIII I9300使用必看玩機技巧
安卓技巧三星Galaxy SIII I9300使用必看玩機技巧
I9300相信已經有很多人入手了,不知道大家知道多少I9300的使用技巧在這裡總結了一下,希望對大家有幫助。如果還有什麼不全的地方,歡迎在下方留言。1. 鎖